Warp 10 3.4.0 has just been released, introducing new features and some bug fixes.

The latest version of Warp 10 (3.4.0) has just been released, introducing new functions and a few bug fixes.
The previous version (3.3.0, June) introduced new interpolation functions. This release takes it further with time-based interpolations and introduces a strong competitor to the well-known BUCKETIZE framework: FILL now has a new signature, and can process multiple series at once. A real time saver to create perfectly aligned time series for your CSV or stacked charts! More details below.
- Pencode can now encode to jpeg, with a user defined quality parameter.
->SETandSET->now accept list or sets.- Introduce hull functions:
LOWERHULLandUPPERHULLallow to compute easily the minimum/maximum envelope of a GTS. Very useful for energy players. - Changed slf4j logging backend to reload4j (log4j 1.2 fork). Warp 10 was never affected by log4j bugs, but we understand that your automatic CVE detector keeps screaming.
- TOKENINFO can expose all the token attributes, when used with tokenattr capability.
- Fix SNAPSHOT of a macro that contains a null element.
- Minor bug fixes and dependency updates.
Convex hulls: for energy industry, and more…
Given a power consumption curve, what is the off-production energy consumption? In French, there is a nice expression that cannot be translated: "le talon de consommation électrique".
Taking the absolute minimum is not the best idea. First, remove the outliers, if you do not trust the measurement, then you need the "shape" of the lower part of the curve, the minimum envelope. This is exactly what LOWERHULL does:
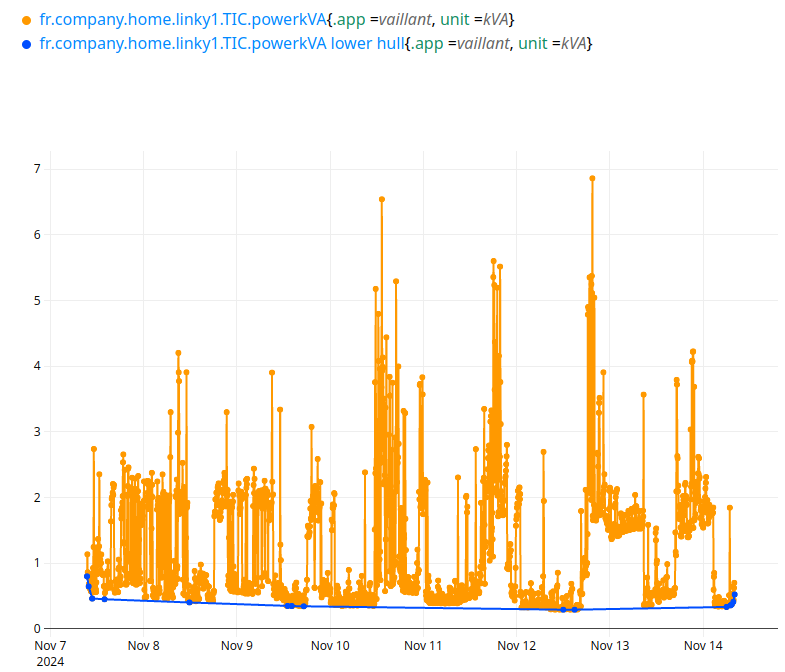
You can try it on the sandbox here.
UPPERHULL computes the upper part of the convex hull: the maximum envelope.
FILL, the new cool kid in WarpScript
"BUCKETIZE first, then REDUCE". We teach this sentence to our WarpScript students… Realign all your inputs before trying to aggregate them. This works perfectly for regular data, but what about GTS from a car? Drive one hour, stay off during 12h, drive 10 minutes, stay off during 24h… If you want to keep precision, you will have to create a LOT of empty buckets.
That's why we introduced FILL in October 2018, but it can only fill two GTS to sync them. FILL recreates missing timestamps that are present in gtsA in gtsB, and missing timestamps present in gtsB in gtsA:
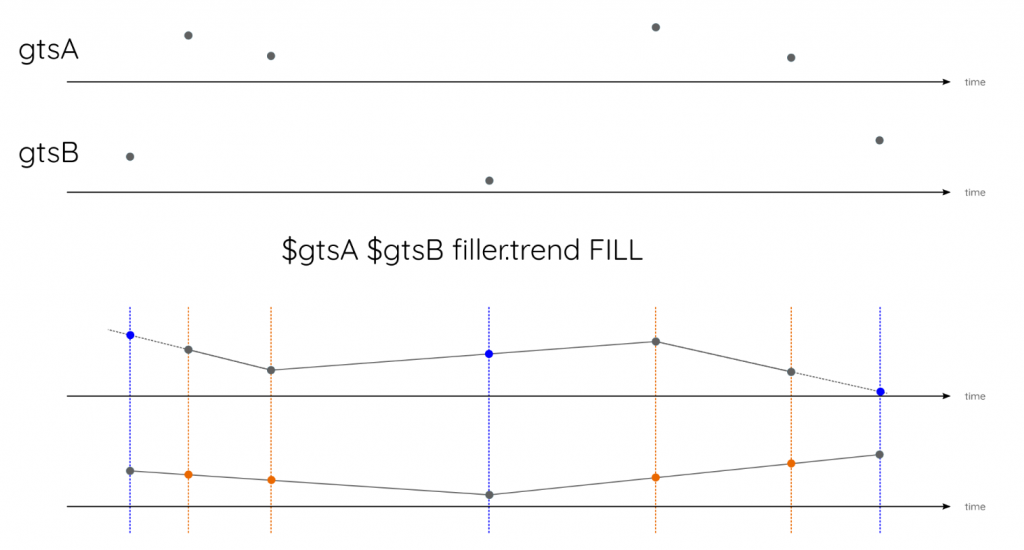
This approach allows complex custom fillers that can build the datapoints in gtsB on the relative tick gaps with gtsA.
But what about filling more than 2 GTS ? And how to fill data from an interpolation function f(time) based on time ? FILL now has a new signature to handle a list of GTS:
$gtsListInput
{
"filler" // the filler function
"ticks" // (optional) if defined, will override buckets. output will not be bucketized anymore.
"invalid.value" // (optional) constant to fill all the buckets or ticks that cannot be interpolated.
"verify" // (optional) when false, the ticks parameter is not deduplicated. Defaults to true.
}
FILLThe new FILL signature can handle a list of N gts, bucketized or not. Here is how to use it.
FILL on multiple bucketized series
Previously, INTERPOLATE was the only function available to fill empty buckets based on timestamps, performing linear interpolation. With the introduction of the new FILL functionality, additional interpolation methods are now supported, including spline interpolation, Akima interpolation, polynomial interpolation, and local regression. Unlike INTERPOLATE, these new fillers do not take into account latitude, longitude, elevation and fill only the values.
Here is an example of an Akima interpolation on a bucketized GTS:
"60V4PLtkSMFQ.0N.4V.Q...LV71wtCeqZkNLV81SuGcL42Wy6sg7.........1hWN4DvSRqxVR6yKeae5xRmQt6zzMCUHhZzN2ZThibqGHYjyfGvEFi_zwCsJjEr_OrN.iMSN85NMA7b5wfvgf.svVbIQXYjxrR4oGjdGu1wzw3ARerNfZ0tUnlXfixZq.2WDI0xiYdtzu73.93EvNqE....4WFG.."
UNWRAP 'input' STORE
$input // one data point per hour...
[ $input bucketizer.last 0 5 m 0 ] BUCKETIZE // we want one point every 5 minutes
{
'filler' filler.akima // with an akima spline interpolation
} FILL SORT
'+filled' RENAME
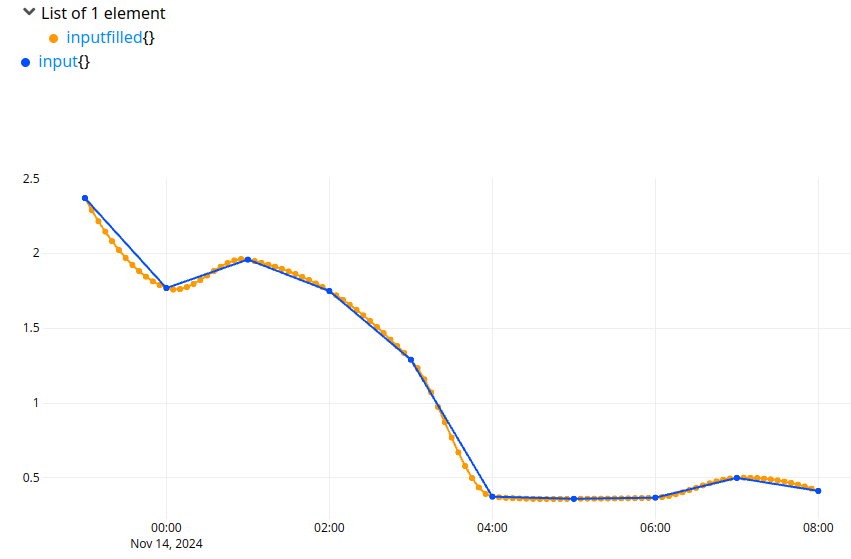
If there is more than one input, FILL will process them one by one (as MAP or BUCKETIZE framework do).
Realigning with FILL before generating a CSV file
CSV generation has already been discussed in this article. The new FILL really simplifies the process of realigning data. Here is an example of a non aligned and irregular dataset.

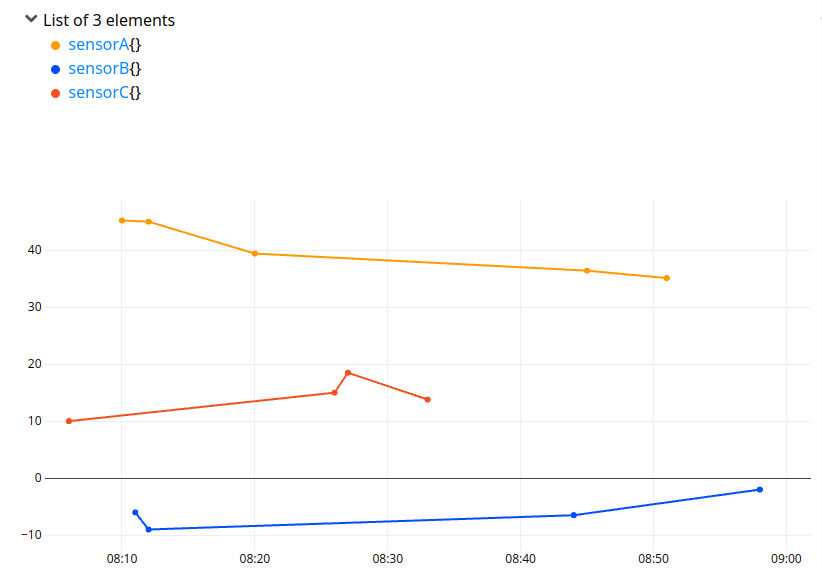
If you use a regular BUCKETIZE + INTERPOLATE, keeping a one minute precision, you will create a lot of buckets:
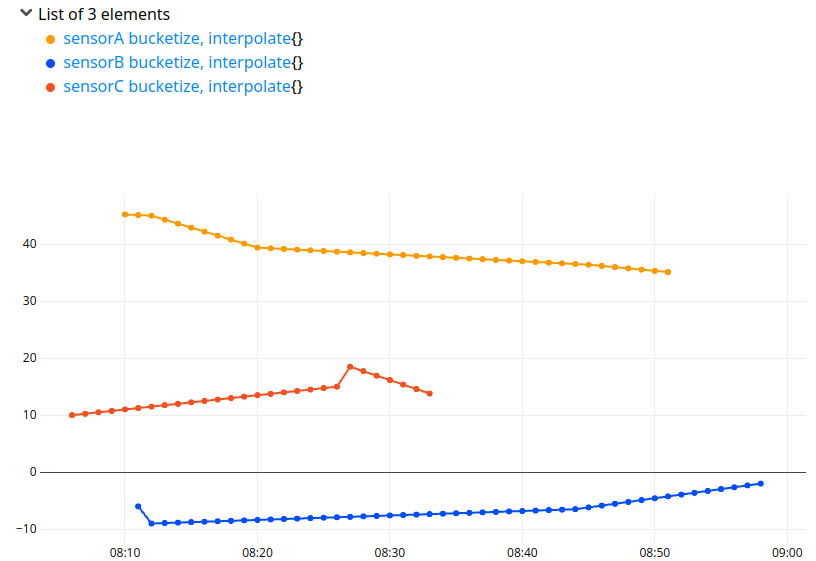
The new trick is to use FILL with the ticks parameter: the function to gather all ticks of a list of GTS already exists, it is TICKS.
$inputs
{
'filler' filler.interpolate
'ticks' $inputs TICKS
} FILL SORT
'+ after FILL' RENAME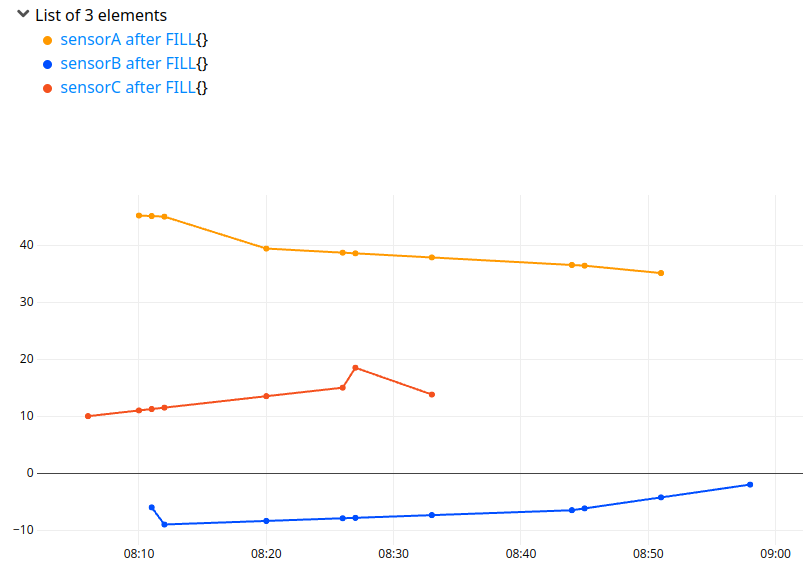
Data are now aligned, but not ready to do a CSV, there are data holes before and after. You can consider to keep the common part of the data, with the COMMONTICKS function:
$inputs
{
'filler' filler.interpolate
'ticks' $inputs TICKS
} FILL SORT
'+ after FILL' RENAME
COMMONTICKS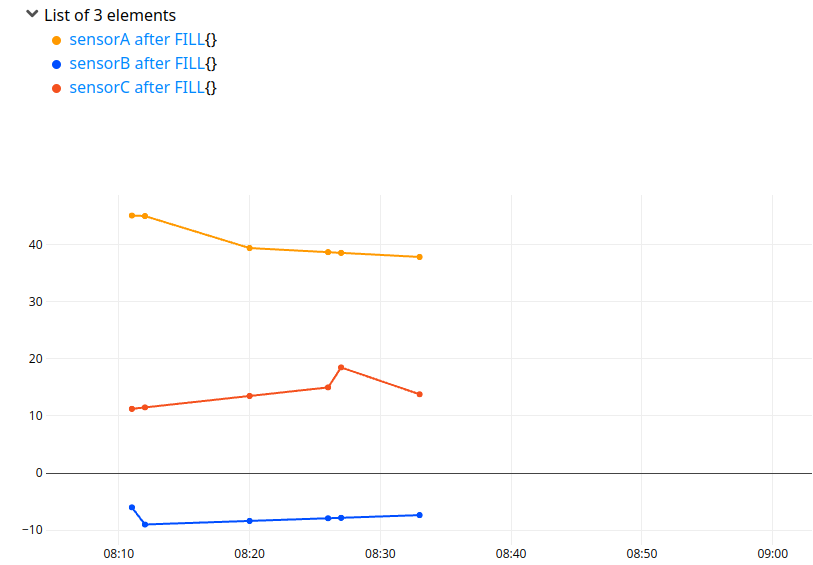
This could easily be converted to a CSV or other column format, and you can choose a different smoothing function among the new ones, such as filler.spline.
If you do not want to lose the information before 8h10 and after 8h33, you can specify an invalid value for FILL:
$inputs
{
'filler' filler.interpolate
'ticks' $inputs TICKS
'invalid.value' 0
} FILL SORT
'+ after FILL with 0 as invalid value' RENAME
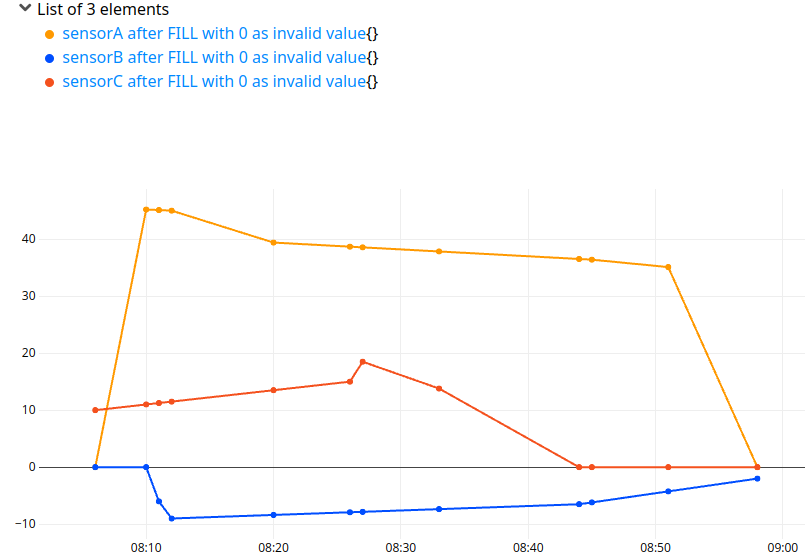
If you carefully choose the invalid value (99999), be confident that the CSV user will understand that the value is not valid. Another approach is to FILL with the previous value and the next value, as FILLPREVIOUS and FILLNEXT do on bucketized GTS:
$inputs
{
'filler' filler.interpolate
'ticks' $inputs TICKS
} FILL SORT
{
'filler' filler.next
'ticks' $inputs TICKS
} FILL SORT
{
'filler' filler.previous
'ticks' $inputs TICKS
} FILL SORT
'+ after FILL' RENAME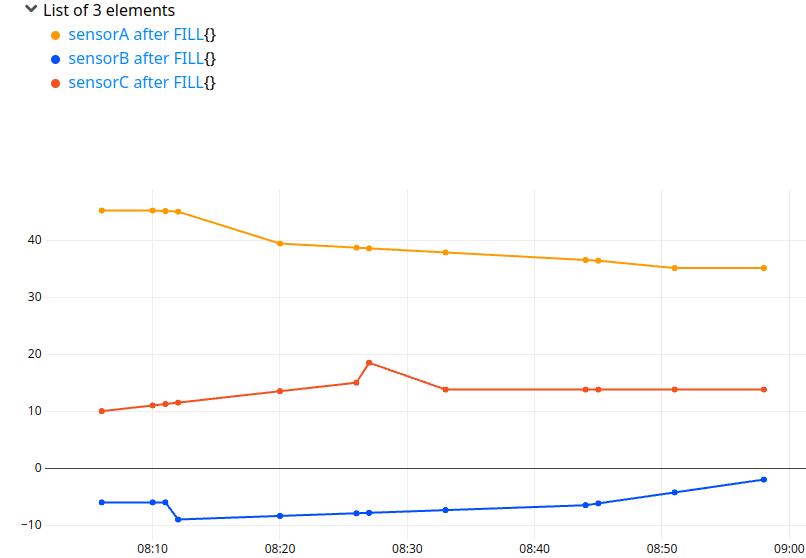
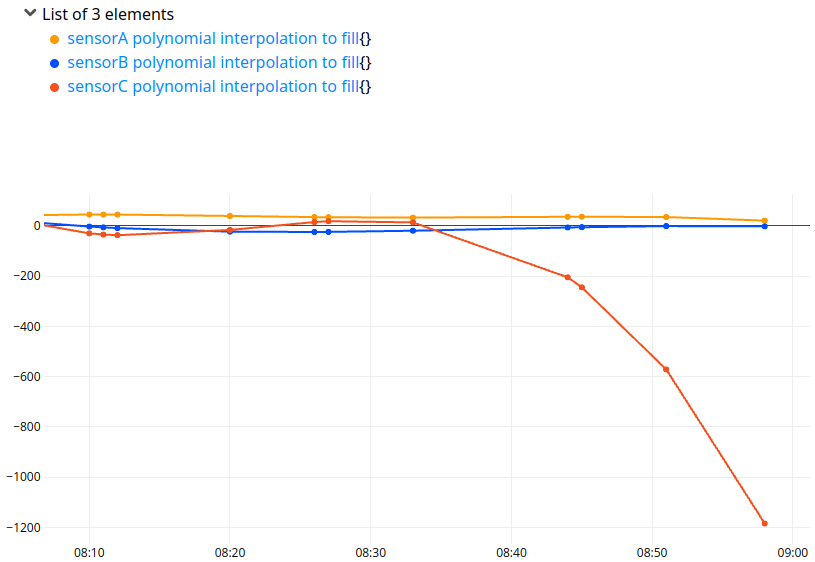
Note that some fillers can interpolate data outside of the range. For example, filler.newton will do a polynomial interpolation… beware of the extremums.
$inputs
{
'filler' filler.newton
'ticks' $inputs TICKS
} FILL SORT
'+ polynomial interpolation to fill' RENAME
Once your data is aligned, you can convert it to a CSV. Here is a full example:
//today, midnight
NOW 'Europe/Paris' ->TSELEMENTS 0 2 SUBLIST TSELEMENTS->
'midnight' STORE
[
NEWGTS 'sensorA' RENAME
$midnight 8 h + 10 m + NaN NaN NaN 45.2 ADDVALUE
$midnight 8 h + 12 m + NaN NaN NaN 45.0 ADDVALUE
$midnight 8 h + 20 m + NaN NaN NaN 39.4 ADDVALUE
$midnight 8 h + 45 m + NaN NaN NaN 36.4 ADDVALUE
$midnight 8 h + 51 m + NaN NaN NaN 35.1 ADDVALUE
NEWGTS 'sensorB' RENAME
$midnight 8 h + 11 m + NaN NaN NaN -6.0 ADDVALUE
$midnight 8 h + 12 m + NaN NaN NaN -9.0 ADDVALUE
$midnight 8 h + 44 m + NaN NaN NaN -6.5 ADDVALUE
$midnight 8 h + 58 m + NaN NaN NaN -2.0 ADDVALUE
NEWGTS 'sensorC' RENAME
$midnight 8 h + 6 m + NaN NaN NaN 10.0 ADDVALUE
$midnight 8 h + 26 m + NaN NaN NaN 15.0 ADDVALUE
$midnight 8 h + 27 m + NaN NaN NaN 18.5 ADDVALUE
$midnight 8 h + 33 m + NaN NaN NaN 13.8 ADDVALUE
] 'inputs' STORE
$inputs
{
'filler' filler.interpolate
'ticks' $inputs TICKS
} FILL SORT
{
'filler' filler.next
'ticks' $inputs TICKS
} FILL SORT
{
'filler' filler.previous
'ticks' $inputs TICKS
} FILL SORT
'+ after FILL' RENAME
<% NAME %> SORTBY "gtsList" STORE
[] "finalCsvMatrix" STORE // the output
// build the the first line and append it to the result
[ "time" $gtsList <% DROP NAME %> LMAP ]
FLATTEN "headers" STORE
$finalCsvMatrix $headers +! DROP
[ $gtsList 0 GET TICKLIST
<% DROP ISO8601 %> LMAP // need to convert us timestamps into something excel can understand
] //take timestamps of the first gts
$gtsList <% VALUES %> F LMAP APPEND
ZIP //convert columns to lines
"dataLines" STORE
$finalCsvMatrix $dataLines APPEND
'CSVmatrix' STORE
Then follow the instructions in this article to use an external Python lib to create a CSV file from the output matrix. Using Python CSV lib is always a better idea than trying to do CSV yourself!
Conclusion
For regulars, the classic routine was bucketize before reduce, but now it's bucketize or fill before reduce!
A new useful one-liner for WarpScript experts:
DUP { 'ticks' ROT TICKS 'filler' 0 filler.value } FILL // fill a list of GTS, return a list of GTS aligned.Read more
Deploying a Distributed Warp 10 instance
How to migrate to Warp 10 3.0?
Introducing BigDecimal within WarpScript

Electronics engineer, fond of computer science, embedded solution developer.