Discover how to deploy Warp 10 on edge to build your IoT platform with data compression, upstream and downstream channel, security by design.

Do you want to build your own Industrial IoT platforms from scratch? Do you want to avoid walled gardens where your data is not really yours anymore? You're not alone, and you just found the right blog to fulfill your needs. I will first explain the concepts behind an IoT platform, then how to do it with Warp 10. You will learn some little-known token features and functions.
As a Time Series Database, Warp 10 can be deployed everywhere a JVM is available. The minimum requirements are 128 MB of RAM, 4 GB of available storage, and a real-time clock. At SenX, we deployed Warp 10 on thousands of devices. The cookbook to deploy safely is always the same, and I will explain the basics here.
Embedding the Warp 10 time series database in your edge devices seems heavy: you will see through this article that it solves common IoT platform problems quickly, with great flexibility.
Why? When?
This is a classic industrial use case: somewhere on earth, you have a machine. You want to be able to collect metrics (upstream channel), and sometimes to tune some parameters on the machine (downstream channel). You want an open-source solution you can run on PaaS or on-premise, you do not want a walled garden provided by an industrial PLC supplier.
Your machine is up 24/24, but you always depend on a random power supply (there could be an outage), and random internet access. Time Series Database world is full of computer monitoring players: the TSDB is always up in a data center, network, or power outage is not even considered. There cannot be a 24h outage in this kind of environment. So, some players do not even consider writing data in the past. You can have one or two months offline, and you don't want to lose data.
Your machine produces hundreds of metrics. But most of them are fixed parameters, some changed once a day, some change every millisecond. You just need to monitor 20 of them. And sometimes, when a failure raises, you need them all, before and after the failure, to understand the failure context.
In your industrial case, you may rely on a 3G/4G/5G with rather expensive data.
Someone may steal and reverse engineer your machine. Keep this in mind for your security model.
In the lifetime of your product, you may define the serial number of the machine very late in the assembly process, or may change it because the maintenance guy swaps one box with another one. In the lifetime of your product, the hardware can fail. And one day, the maintenance guys will replace the datalogger with another one borrowed on another machine. And you don't want this to mess up your data.
To sum up, your IoT platform needs:
- An upstream channel
- A downstream channel
- A local cache
- Custom sub-sampling and efficient compression on the upstream channel
- A good security model
You need edge computing to preprocess your time series. And a central database able to deal with this use case. So you need a solution like Warp 10.
The local security model
Let me start with the simplest: the local database. On your device, you have apps that poll different industrial buses (from Modbus to CAN to basic UART). This article will not describe how to make these apps, it is too specific to your product. Here is the specification for these apps:
For high-frequency data (greater than 1Hz), buffer data the simplest way: for each channel, you need to keep timestamp and data value, that's just a two-column table.
Every 10 or 30 seconds, flush the buffers, serialize data and push them into local Warp 10 (http://localhost…). I will detail this step later. If you want to be able to change parameters on the bus with the downstream channel, your apps may provide a local API for easy interaction.
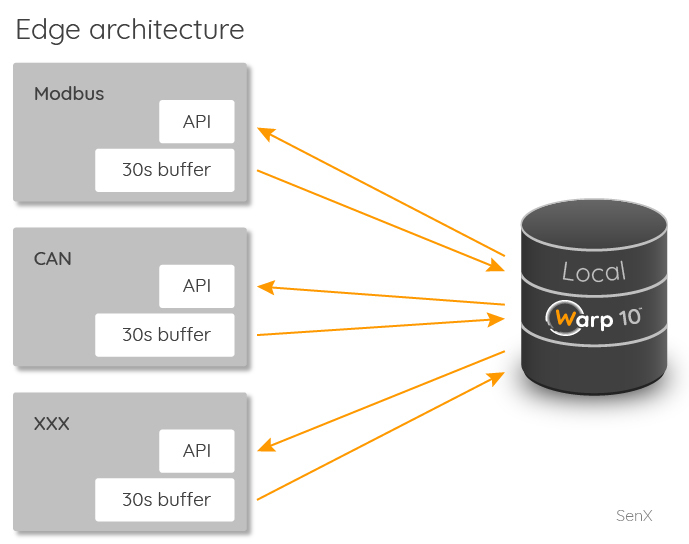
The local Warp 10 will only listen on 127.0.0.1. It does not need to listen on every interface except during the development phase.
It means all your products can share the same local tokens. If someone can log in on 127.0.0.1 to read or write data, your system is compromised anyway.
The global security model
Reverse engineering of one stolen system among thousands must not impact you.
So, all your systems MUST have unique read and write tokens. You need to generate a huge list of tokens that cannot read or write data of other systems. Each token pair is isolated from the others.
With Warp 10, it is really easy to produce as many pairs of tokens as you need. Each pair will have a different label, for example, a label called "TokenUUID". Whatever the FETCH or UPDATE operation you will do on the central database with this pair of tokens, the token will enforce TokenUUID label. If your business is B2C in Europe, your IoT platform will be GDPR ready by design.
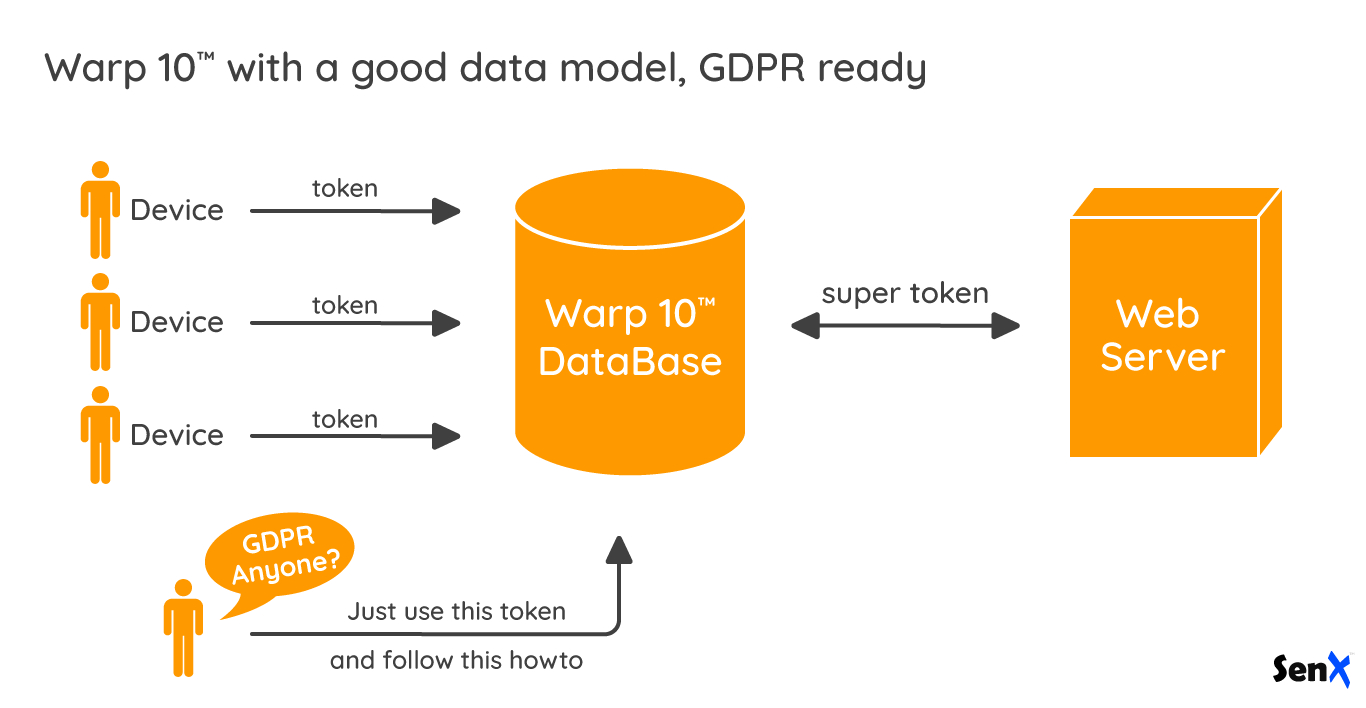
The data model
Keep it simple. If you already have an ontology in your company that defines channel names and units, stick to it. If you do not have one, it is time to build one.
Do not bloat the labels list. Stick to essential things. If your CPU does provide a serial number, it is a good idea to have a SystemUUID label on each of your series. You will have a TokenUUID enforced by your tokens. As previously explained, if the serial number is defined late in the process, or if the maintenance team or your customer may permute systems, the serial number cannot be hard-coded. The best design is to be able to read the serial number in the data you collect from your machine and append it dynamically before uploading data.
Example: engine1.exhaust.temperature {systemUUID=xyz,serial=xxxxx} 604.5
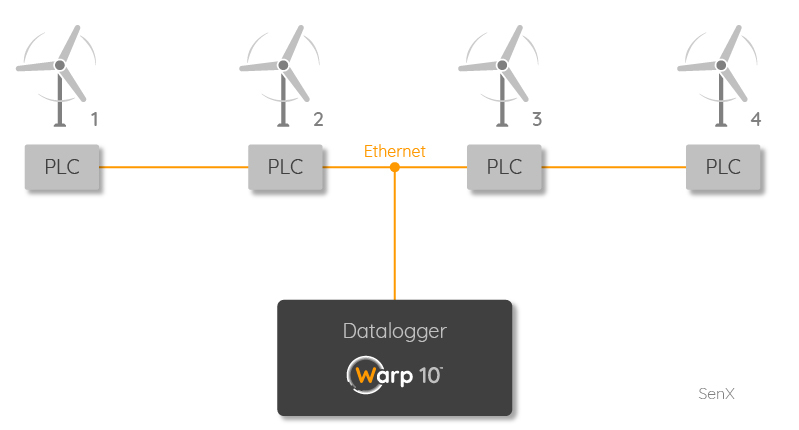
If you connect one local database to several systems, for example, one local database to monitor 4 wind turbines, you will add the turbine number in the labels. Example:
turbine.active.power {systemUUID=xyz,farm=48,windturbine=2} 275
There is no point to add "unit=kW" because you know you will always store kW for this information.
If you have data with a strong correlation (for example, a sensor that always provides a value + a dynamic error margin), you may store both in the same series, with multivalue.
You can choose to store raw data. For example, you can store a single standard can frame (8 bytes) as a LONG value in a GTS. For longer frames, you can store as binary data. But choosing not to decode data on the edge device make it impossible to fine-tune your upstream channel. You will need more bandwidth.
Data model is a compromise: there is always a trade-off between size, bandwidth, ease of analysis. Do not over-engineer your first release. SenX can help you, this point is very important and really depends on the use cases. Contact SenX at contact@senx.io for more information.

Prepare your system
Time to code! In this example, I will take a Raspberry as an example, but it is applicable to any SBC or compute module.
In an industrial process, you want to be able to deploy software as fast as possible. So, you will not repeat every installation step on every system. You do it once, then you make an image of the system that you will copy on all the new systems. If you use a Raspberry, you will do an image of the SD card, then duplicate SD card.
Prepare an ssh key set to access this system: keep the private key safe, using tools your company provides you to store and share safely secrets. Then put the public key on your device (for example, in /root/.ssh/authorized_keys). I won't detail this step, it is heavily documented on the Internet.
Secure the device: by default, Raspbian allows user pi to log in with raspberry as a password. Define a really strong password, then disable password login in ssh configuration. Customize /etc/ssh/sshd_config to do so.
Then, follow our getting started to deploy Warp 10 to /opt/warp10/. You need Java 1.8 runtime. Since Warp 10 2.7.3, you do not need python anymore.
Customize Warp 10
It is time to create several configuration files in /opt/warp10/etc/conf.d/. The first one will customize limits and timeouts. It is very important for an edge application to configure correctly timeouts.
Create /opt/warp10/etc/conf.d/90-projectsettings.conf:
# no limits
warpscript.maxops = 1000000000
warpscript.maxops.hard = 20000000000
warpscript.maxbuckets = 100000000000000
warpscript.maxbuckets.hard = 200000000000000
# enable rexec extension
warpscript.extension.rexec = io.warp10.script.ext.rexec.RexecWarpScriptExtension
# 1 hour timeout on REXEC
warpscript.rexec.timeout.connect = 3600000
# REXEC read timeout in ms (default = 0, no timeout)
warpscript.rexec.timeout.read = 3600000
# Here you can define your company domain for example
warpscript.rexec.endpoint.patterns = .*
# activate the SHM extension
warpscript.extension.shm = io.warp10.script.ext.shm.SharedMemoryWarpScriptExtension
# push up the time in loop limit to one hour
warpscript.maxloop = 3600000
warpscript.maxloop.hard = 7200000
#if you want to be able to schedule fast runners
runner.minperiod = 1000
#enable runner multithreading
runner.nthreads = 3
warpscript.repository.ondemand = true
warpscript.repository.refresh = 120000
warpfleet.macros.validator = utils/macroValidator
# put any secret here to hide warning at Warp 10 startup
warp10.report.secret = de3e5ae0-b00b-4c43-8327-b16667ff0ba1
# local tokengen (just to generate local tokens)
warpscript.extension.token = io.warp10.script.ext.token.TokenWarpScriptExtension
token.secret = localSuperSecret
# listen to localhost only
standalone.host = 127.0.0.1Create a temporary configuration file that will only be used during the development phase, for example: /opt/warp10/etc/conf.d/99-tempDevSettings.conf:
# listen to localhost only
standalone.host = 0.0.0.0Note there is no point here to have strong secrets here. If someone breaks into your system or reads the SD card with another computer, it can access to Warp 10 deepest secrets anyway.
At least, don't forget to limit the RAM usage of Warp 10 by tuning the heap size WARP10_HEAP in /opt/warp10/bin/warp10-standalone.sh. It depends on your hardware.
Generate local tokens
Using your favorite WarpScript IDE, on your computer, prepare a WarpScript to generate tokens on your edge target.
Unless you plan an obsolescence of your systems, 100 years lifetime is a good choice.
You can now add them to your configuration. Create /opt/warp10/etc/conf.d/91-localTokens.conf:
# local write token
localWT@tokens = zrv9gd3cR.TMp..xSxsyT2EKS6HR1Dcwk9iojRi8fBtFIGZGBZiPeE1qv63thYCk_JKj7FX1JxlPvLX1lO3n2ok.sPLao
# local read token
localRT@tokens = sjXVdv.QEMUCp20TmcaUERasyyelaRIwuaXcrdQKMDaNAEdxTEHnhyzH5_KQDGMFDo33mRi.a6Q2vECseTeuJoFRkSoZg90sgZK94EPvzZ.a2KGl5zLWXigikIt means that all the macros located in /opt/warp10/macros/tokens/ will be able to access local tokens with "localWT" MACROCONFIG, or "localRT" MACROCONFIG.
So, you can now create a macro to read local tokens from everywhere. Create /opt/warp10/macro/tokens/localTokens:
This macro will be useful for the data ingestion in a few paragraphs.
Finish your first image
At this step, you can add other dependencies you need for your project, update the system, switch it off, and make an image of your work that you will reuse for mass production. During mass production, you will need to write tokens to access the remote database (in a new configuration file), install your apps, copy the WarpScript, and remove the /opt/warp10/etc/conf.d/99-tempDevSettings.conf file.
Generate remote tokens
On your Warp 10 instance, you can also activate the TOKENGEN extension, with a really strong secret. Generation of tokens is just a loop in WarpScript to generate 1000 pairs of tokens. In the security model, you will include more information in the token:
- A new label, randomly generated for each token pair, to isolate tokens
- A write token attribute to disable delete endpoint access:
.nodelete - A write token attribute to disable update endpoint access:
.noupdate - A write token attribute to disable meta endpoint access:
.nometa - A write token attribute to disable writing too far in the future:
.maxfuture - A read token label called "commands".
There are more options for token attributes, but the most important is that a compromised system cannot delete the data collected by the device, cannot overwrite them, or cannot pollute your IoT platform by adding data in the future or deep in the past. If you are really sure that you will never get any outage longer than 3 months, you can also prevent writing in the past with .maxpast token attribute set to 3 months. The extra-label enforced by the read token is here to make sure a compromised system cannot read its own data pushed in the central Warp 10 database.
Here is the WarpScript to do so, assuming the TOKENGEN extension is enabled with a really strong secret:
The JSON output will look like:
[
[
{
"tokenUUID": "d3094295-c007-432a-8e46-1b0e77d2b115",
"readToken": {
"ident": "c473cc4622aef164",
"id": "tokenRead",
"token": "7Udn4PyVhdZgyjAYncx5u4FjnyPX3iEy8VA_96iJtMocEV3TkkspzjYsrOhzRt68ZITWdaGQ4ML0H0NW9Z7A6gZceiUnLliZYw4HFsG3d3u0VSzpbWqh7LvhNkzlpbjffOi.Uu.Zw6iiO2YUCUuHEyYl7q7Ei8AVjS_6pnbpCUyF3zJxNU8ImgGO5Nw..MYtkjEvK.YzEfOfWuNWHQ4rcSbmcRhln_VIqa0F24wVIYgVdlbsigoQUF"
},
"writeToken": {
"ident": "9a3bba5ea32d94a7",
"id": "tokenWrite",
"token": "x2M837a_hY4rukVCySd3KPsq_LQpfQ.sxfpn.Nt3GHy2GPyZHObojb_YvaWoWMyPfMsWBoNnYiXaWJnwuvdSKc0h2eZIGAKfVO4aAjYkF0Q_k.oKYEjRXSJpXge3WVr80FuXJDK7RgnYdr.HkNoybPemrs0GIEt0tJP4YV9zYyQzkemQJ6cvmVi46uVpglgMlar2zvJhO0NAbzZql.Ebnk"
}
},
{
"tokenUUID": "886cb32e-ee6a-4b3b-8179-6c633f5381d6",
"readToken": {
"ident": "d35252a284e4f44e",
"id": "tokenRead",
"token": "Vj14I74VQPy47dqeky14dveUj_X1I.Rd8QlQOjEJhfPW_ds5Kwgjn0zLVfTeJeOKTljk1beHq0k02dG78rcvRksOVtaTnMYVun81Ue5ZbYLqLey2_6h69fKQszhV.vPPNVXhcntF7_ZzSzD1IDzR7.eM.XSDHafzpGw6rPwlACo4nUA6VAppBrNqOl36o.5D.YX0npBb.wP9BxJZ1bsKW6juccRDwIlTv8UEnvkX.aZewr9Rf89jgV"
},
"writeToken": {
"ident": "559377b4264835b2",
"id": "tokenWrite",
"token": "RriPur2JKwf3SqBCJWjdOfTcUWeL367koz0TAoNCCh7iOi2YStBmDiaTQQWq0HwKyVNtTcQQDgM78EVdPi5oSYGjR48v7KXRLdmp5sKEngQHNMdtK5B2Ejjan_GyHy9XPrRRO5XqwY4aIz2958URN.51D3jfvlLWS1N2snctlzZjKTbRklbYuavD1YK2VNOwHiGh_wg5KcrCOmHvGCXGCV"
}
}, ......Save the output JSON safely with your project keys and sensitive data. When you will write the deployment for mass production, it will be very easy to get a token pair in this list and generate the configuration file for each system. If one of your systems is corrupted or stolen, you can revoke the token using Warp 10 revocation list, but to do so, you need the 64 bits "ident" you see in the JSON output.
SenX does not activate TOKENGEN function on its SaaS, but if you choose one of our SaaS plans, we can generate these tokens for you.
The local ingestion
As explained before, all the apps on your system will keep a buffer, to flush it every 30s or so in Warp 10.
You can serialize data in your app in the GTS input format, then use http://localhost:8080/api/v0/update endpoint. It will work, but it is not the most flexible way.
You can instead serialize your data either in JSON or in GTS input format and include the data as an argument of an "ingest" macro to forge a WarpScript that you will push to http://localhost:8080/api/v0/exec endpoint. The WarpScript your app will generate will look like:
<'
Serialized data here, in a multiline string
'>
@myproject/ingestDataThen you create a macro /opt/warp10/macros/myproject/ingestData.mc2, that basically contains:
If disk space is critical in your application, you can decide here to make a first optimization with RANGECOMPACT. This is far easiest to call RANGECOMPACT with WarpScript than to implement it in every application. It is also easier to manage the serial number or device number in WarpScript than implementing that in all the apps that collect data on the system. As you do not need the streaming capabilities of the update endpoint for a small 30s batch of data, it is a lot more flexible to forge a small WarpScript and to use the exec endpoint. If you change your mind during the product lifetime, you just need to remotely update the /opt/warp10/macros/myproject/ingestData.mc2 file.
The upstream channel
Now, you need to push data from the edge Warp 10 database to your central Warp 10 database.
How often should you upload the data?
The maximum period depends on the available RAM on the system. The data chunk you will load with a FETCH must fit in RAM. You can do tests until your scripts fail with OOM error (out of memory).
The minimum period depends on your bandwidth and data cost. If you push data every 30 seconds, you cannot compress a lot, and you have the HTTP overhead. Having data in near real-time costs a lot with an LTE phone plan.
How do you schedule this?
Warp 10 already include a scheduler. You do not need any external application for this.
How to deal with a long history?
If your system was offline during a month, you have hours of data to push. The simplest way is to push 8 hours of data every hour, for example. A one-month history will be uploaded in 4 days. You can go faster if more than 8 hours fit in RAM, or if you push data every 5 minutes.
I sell products in countries where I do not trust the network operators, can I add an encryption layer?
If you fear HTTPS certificate substitutions, you can encrypt the serialized data. WarpLib provides all the functions you need for symmetrical and asymmetrical encryption.
The simplest implementation of the upstream channel is just one WarpScript you can create in /opt/warp10/warpscripts/myproject/3600000/upload.mc2 (the scheduling period will be 3600000 = 1 hour):
- Read the last successful upload in the "upload.done" GTS, using FETCH with count = 1. Store the timestamp as
startvariable. - If "upload.done" do not exist, find the first datapoint in the local database, and take it as
start. - Fetch from
starttostart+ 8 hours - Call a macro to process data (subsampling, filter, LTTB…), depending on your data model choices.
- SNAPSHOT the final GTS list.
- Forge a WarpScript that will evaluate the snapshot with EVAL, then UPLOAD it with the remote token.
- REXECZ this forged WarpScript to your remote instance exec endpoint.
- if REXECZ is successful, add
start+ 8 hours
You can find examples in the Server to Server tutorial here.
The downstream channel
That is the key feature of an IoT platform. Observation is great, but you also need to interact with your system. The idea is simple: Every xx minutes, your edge system will read a GTS on the remote database. This GTS can contain every command you can imagine: an update script, a call to one of your apps through a local API to set a parameter on your machine… Imagination is the limit.

Create /opt/warp10/warpscripts/myproject/600000/commands.mc2, and build a WarpScript to read a GTS from the remote Warp 10 instance, using the remote read token. As we enforce an extra "command=true" label, you must include it in your fetch. Here is an example:
Again, you can find examples in the Server to Server tutorial.
What kind of command can I launch from Warp 10?
Warp 10 comes with WEBCALL function. If one of your apps has an API to write a parameter on Modbus, for example, you can imagine that your command is a JSON like:
{
"command" "modbusWrite"
"type" "coil"
"value" true
}In WarpScript, you can push this command to a local API:
Warp 10 also comes with CALL function. You can imagine any kind of shell script to execute remote commands. To fully understand CALL and WEBCALL, follow this documentation.
Log rotation
The simplest implementation is to delete the oldest local data every day. The retention time directly depends on your available disk space. Create a WarpScript to be scheduled once a day, for example: /opt/warp10/warpscript/myproject/86400000/commands.mc2:
At SenX, we developed a LevelDB plugin to speed up deletion. This plugin is also very useful for edge, it limits NAND flash wearing.
Use IoT extensions
With WarpScript latest features and extension, you can build far more advanced strategies:
- Use LevelDB extension (commercial) for fast delete, saving LevelDB recompaction after delete.
- Use HFile extension (commercial) to save cold data longer in really compact files.
- And use File extension (free) to generate custom files for other apps, or to check remaining free space on disk within WarpScript.

Conclusion
You may already know that Warp 10 as your central time series database solves the requirements of connected devices, with a strong security model.
If your hardware is powerful enough, embedding Warp 10 in your device allows you to solve more challenging problems, such as efficient offline storage and bandwidth issues.
If you want to build an IoT platform that really belongs to you, contact us!
Read more
Connecting a BeerTender® to Warp 10 using MQTT on LoRaWan with TheThingsNetwork
Warp 10 for IoT: GDPR compliant before GDPR even existed
Etch-a-Time Series: a Raspberry Pi, a laser and Warp 10

Electronics engineer, fond of computer science, embedded solution developer.