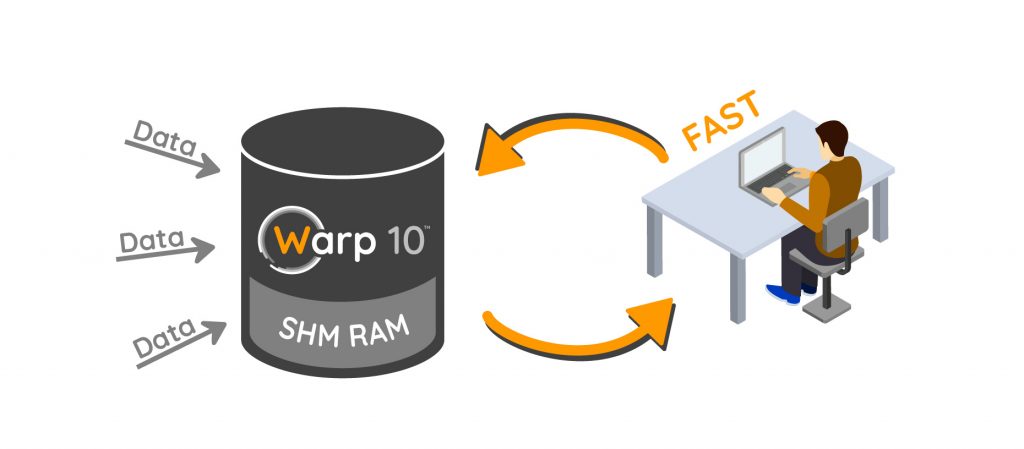
SHM is a Warp 10 extension that allow to keep data in RAM. It speeds up data scientist job!

Warp 10 storage layer is fast. Especially if backed up by an SSD.
On my laptop, fetching some vehicle speed data, around 25M points in 2700 series takes approximately 30s. Fine. But… I am testing my WarpScript braking energy models on these data in interactive mode. It means I can waste 30s * 100 in a day, waiting in front of my Visual Studio Code.

If the task is CPU intensive, I sometimes push intermediate results in Warp 10 with UPDATE and META. Fetching these results is less time-consuming than recomputing them.
Our most demanding customers set up some in memory instances for this. They fetch data once in their big Warp 10 distributed datalake (using REXEC, see server to server tutorial), and push the data in the in memory version. They also use automatic replication (see datalog) to always get the latest data. The next script iteration, data is already there… in RAM. Blazing fast access!
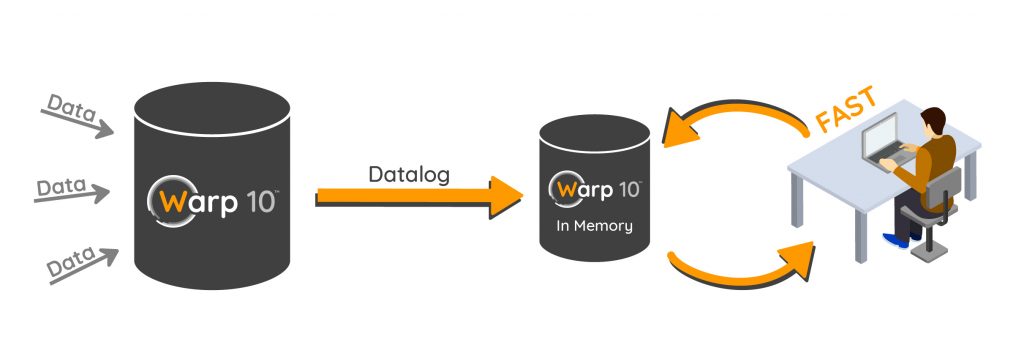
I only have a laptop with a few GB of free RAM, so I cannot afford to replicate all my database in RAM. Each time I FETCH data in a WarpScript, I store these data in RAM. How can I keep inputs or intermediate results in RAM for the next iteration? That's the purpose of the SHM extension.
Learn more about why time series are the future of data.
SHM = SHared Memory
SHM is a built-in extension since Warp 10 v2.0.0. It means you just need a few lines in your configuration file to enable it: Edit your ./etc/conf-standalone.conf, add the following lines:
# Activate SHM extension
warpscript.extension.shm = io.warp10.script.ext.shm.SharedMemoryWarpScriptExtension
# SHM settings, time to live in milliseconds : 4 days retention
shm.ttl = 345600000Restart your Warp 10 instance. You now have three new functions: SHMSTORE, SHMLOAD and MUTEX.
The long TTL allows me to leave on Friday, and still find my data on Monday morning!
SHM basics
The latest Visual Studio Code plugin includes this snippet, just type shm then Enter:
<%
<%
//try to read data from SHared Memory
'gtsList' SHMLOAD
DROP
%>
<%
//when not found, store data in SHM
[ $token 'classname' {} NOW 365 d ] FETCH
'gtsList' SHMSTORE
%>
<%
//finally, load the reference from SHM and store it
'gtsList' SHMLOAD
'gtsList' STORE
%> TRY
//analytics on $gtsList
$gtsList
%>
'myMutex' MUTEX //prevent a concurrent execution on the same SHM dataRule n°1: Remember SHared Memory. If two scripts try to access the same variable, things could go wrong. Using a MUTEXcall is mandatory. The mutex name is important, it is attached to this gtsList variable the first time you store it. Trying to access gtsList from a different MUTEX call will raise an exception.
Rule n°2: Use SHMLOAD in a try catch structure. If the data is not available (TTL expired, first instance launch), SHMLOAD will raise an exception.
Rule n°3: Store lists or maps, change values in the list or map. If you want to change the SHM variable, erase it before storing again a new object reference or a new primitive.
SHM for power users
- You can keep every kind of object in SHM, not only Geo Time Series!
- Erase an SHM variable is easy :
NULL "variable" SHMSTORE - Time to live is reset every time you read the variable. If you want to keep some data indefinitely, just create a runner to read it periodically.
- If you can work on a server or computer with lots of RAM, don't forget to increase your JVM RAM settings! Remember the default Warp 10 configuration is to use 1 GB of heap memory. Edit
bin/warp10-standalone.shwith your favorite text editor, customizeWARP10_HEAPandWARP10_HEAP_MAX, save and restart your Warp 10 instance. - Instead of pushing all your data to Warp 10, you can easily set up some custom cache or write on change mechanisms!
Conclusion
My current project is really close to an automotive data analyst. I am currently using a 128 GB server in a datacenter. SHM extension saves me lots of time in a day!
Read more
Infographic: What happened in 2020 for SenX?
2 Fast 2 Curious: JMH Benchmarks in WarpScript
HTTP Plugin

Electronics engineer, fond of computer science, embedded solution developer.