Schedule Warp 10 tasks with runners, like down-sampling, archiving, deletions, computations and so on.

Ever wonder how to downs-sample old data or to do some computation periodically? Warp 10 uses runners for that. We will cover the basics of runners and a simple use case.
Runners are scheduled tasks in Warp 10, written in WarpScript.
| Since version 2.11.0 of Warp 10, a runner can decide when to reschedule itself. Dynamic scheduling is now really easy within WarpScript. Read this article to learn more. |
How to basic
In your Warp 10 installation folder, there is a directory called warpscripts which contains, by default, this folder hierarchy
/path/to/warp10
[...]
|- warpscripts
|- test
|- 60000
|- runner.mc2.DISABLEWhat it means: for the domain "test", each "60000" ms, all files with the "mc2" extension will be executed as a WarpScript.
Let's test it: rename runner.mc2.DISABLE to runner.mc2 and edit it:
//
// Warpscript code for this runner
// This script must have a '.mc2' extension.
//
'token with debug extension capability' CAPADD
NOW ISO8601 LOGMSGor an easier understanding of runners' behavior, we will print debug messages to the Warp 10 process log output.
Since Warp 10 3.0, debug is built-in and capability protected. To use STDOUT, you just need a token with the debug capability set to an empty string. Read this article for an example of token generation.
If you still work with Warp 10 2.x, you need to follow these instructions. Enable the debug extension in Warp 10 by adding this line to your personal configurations (/opt/warp10/etc/conf.d/99-personalconfig.conf), and restart Warp 10:
warpscript.extension.debug = io.warp10.script.ext.debug.DebugWarpScriptExtensionNow restart Warp 10 and have a look at the file: /path/to/warp10/logs/warp10.log:
tail -f -n 100 /path/to/warp10/logs/warp10.logYou will see a line per minute (60000 ms) :
[1632130303832] 2021-09-20T09:31:43.832517Z
[1632130363841] 2021-09-20T09:32:43.841663Z
[1632130423848] 2021-09-20T09:33:43.848062Z
[1632130483852] 2021-09-20T09:34:43.852193ZOf course, you can add any subdirectory you want according to your domain (instead of using "test") and any subfolder named by the desired frequency in ms, i.e.:
/path/to/warp10
[...]
|- warpscripts
|- senx
|- 10000
| |- myRunner.mc2
| |- myOtherRunner;mc2
|- 30000
|- anotherRunner.mc2 There are some configuration keys in the Warp 10 configuration file /path/to/warp10/etc/conf.d/10-runner.conf, have a look.
Sample use case
Imagine we have data (random data in our case), we want to do some computations (subsampling with the mean value) and store it for later use.
First, generate a random series with a point every 10 seconds:
NEWGTS 'gts' STORE
0.0 'v' STORE
// for (i = 1; i <= 50000; i++)
1 50000 <%
'i' STORE
NOW $i 10 s * - 'ts' STORE // computed timestamp
$v RAND 0.5 - + 'v' STORE // computed value
$gts $ts NaN NaN NaN $v ADDVALUE 'gts' STORE // add datapoint
%> FOR
// display result
$gtshttps://snapshot.senx.io/0005cc912308cdc5-0-2-282dfd693a5467a9

Learn more about Random Numbers.
Now test the hourly mean value computation in WarpStudio:
NEWGTS 'gts' STORE
0.0 'v' STORE
// for (i = 1; i <= 50000; i++)
1 50000 <%
'i' STORE
NOW $i 10 s * - 'ts' STORE // computed timestamp
$v RAND 0.5 - + 'v' STORE // computed value
$gts $ts NaN NaN NaN $v ADDVALUE 'gts' STORE // add datapoint
%> FOR
// retrieve the last timestamp
$gts LASTTICK 'last' STORE
// keep only the hourly mean value
[ $gts bucketizer.mean $last 1 h 0 ] BUCKETIZE // the sub sampled series
$gts // the original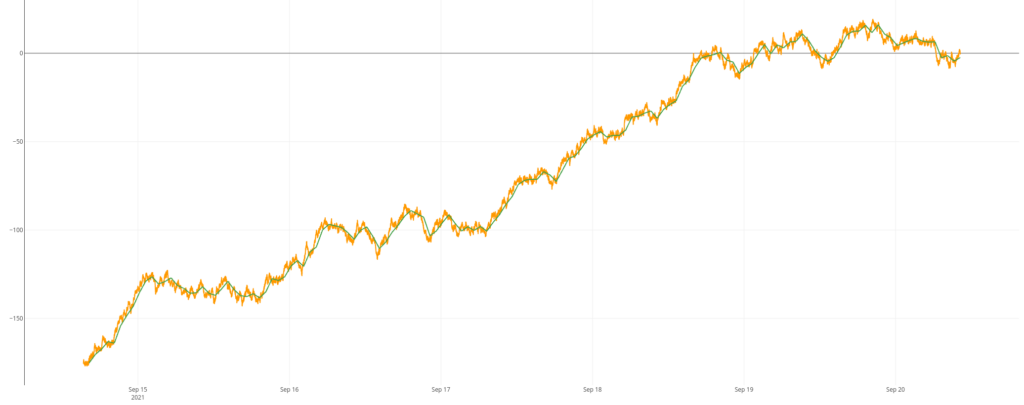
It's time to code our runner.
We will code a runner dedicated to data insertion, a data point each second with a value shared through SHM. (Read this blog post about SHM!)
Now edit /path/to/warp10/warpscripts/test/1000/randomData.mc2:
// Generates a random datapoint each second
<%
<%
// try to read last value from SHared Memory
'value' SHMLOAD 'v' STORE
%>
<%
// when not found, set default value
0.0 'v' STORE
%>
<%
// finally, load the reference from SHM and store it
$v RAND 0.5 - + 'v' STORE // computes the new value
NULL 'value' SHMSTORE // empty the store
$v 'value' SHMSTORE // save it in shared memory
NEWGTS 'random' RENAME 'gts' STORE // create a new series
$gts NOW NaN NaN NaN $v ADDVALUE // add datapoint
'<your write token>' UPDATE // insert it
%> 'myMutex' MUTEX // prevent a concurrent execution on the same SHM dataYou can have a look at the generated series:
[ '<your read token>' 'random' {} NOW 1 h ] FETCH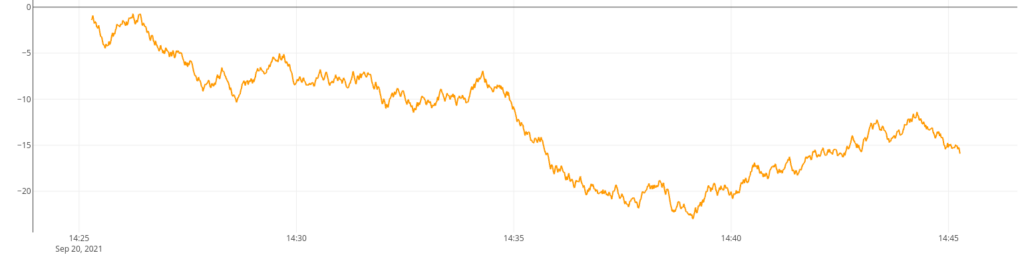
Now we will code a new runner which:
- Runs every minute
- Fetches the last 5 minutes of data
- Computes a moving average over a window of 5 minutes (or whatever you want)
- Computes the mean value of all the values of this time window (this is the sub-sampling, 1 point per 5 minutes, but it is just an example)
- Inserts this new value as a GTS
- Deletes all data points older than one hour.
Now edit /path/to/warp10/warpscripts/test/60000/moving-avg.mc2
// get the last 5 minutes of data
[ '<your read token>' 'random' {} NOW 5 m ] FETCH 'gts' STORE
// computes the upper time boundary as a plain minute
$gts LASTTICK ->TSELEMENTS [ 0 4 ] SUBLIST TSELEMENTS-> 'last' STORE
// computes the moving average
[ $gts mapper.mean 5 m 0 0 ] MAP 'gts' STORE
// computes the mean value
[ $gts bucketizer.mean $last 0 1 ] BUCKETIZE 0 GET
// rename the resulting GTS
'random.avg' RENAME 'gts' STORE
'<your write token>' 'token' STORE
// insert the resulting GTS
$gts $token UPDATE
// delete old datapoints
$token 'random'
MINLONG // start timestamp
NOW 1 h - // end timestamp
MAXLONG // count
DELETEAfter a while, you can see the result directly in WarpStudio:
[
'<your read token>'
'~random.*' {}
NOW 2 h
] FETCH 
Going further
In real life, of course, you will have to handle real data and perform more realistic computation. But the concept remains the same.
You should use macros instead of having all your logic in runners. Your runners should just call macros. You should even automate the deployment of your macros.
And finally, do not delete your data, make archives, into a S3 for example! You never know if you will need it someday.
| Learn advanced features of Warp 10 scheduler: Runners are an easy way to automate WarpScript, without any new external component. |
Read more
Warp 10 Docker Image - Next Generation
Alerts are real time series
Data replication with Warp 10

Senior Software Engineer