Comparing Flux and Warp 10 WarpScript on simple analytics use case. Keep in mind WarpScript was designed for timeseries analytics !

This article follows Keep it simple.
Again, let's compare InfluxDB and WarpScript
In this article, David G. Simmons corrects his CO2 sensor with room pressure and temperature:
ppm CO2 corrected = ppm CO2 measured * ((Temp measured * Pressure Reference ) / (Pressure measured * Temp Reference))
(constants in bold)
He wrote the flux code below :
Tref = 298.15
Pref = 1013.25
Tmeas = from(bucket: "telegraf")
|> range(start: v.timeRangeStart)
|> filter(fn: (r) => r._measurement == "environment" and (r._field == "temp_c"))
|> fill(column: "_value", usePrevious: true)
|> aggregateWindow(every: 30s, fn: mean)
|> keep(columns: ["_value", "_time"])
CO2meas = from(bucket: "telegraf")
|> range(start: v.timeRangeStart)
|> filter(fn: (r) => r._measurement == "k30_reader" and (r._field == "co2"))
|> fill(column: "_value", usePrevious: true)
|> aggregateWindow(every: 30s, fn: mean)
|> keep(columns: ["_value", "_time"])
Pmeas = from(bucket: "telegraf")
|> range(start: v.timeRangeStart)
|> filter(fn: (r) => r._measurement == "environment" and (r._field == "pressure"))
|> fill(column: "_value", usePrevious: true)
|> aggregateWindow(every: 30s, fn: mean)
|> keep(columns: ["_value", "_time"])
first_join = join(tables: {CO2meas: CO2meas, Tmeas: Tmeas}, on: ["_time"])
|> fill(column: "_value_CO2meas", usePrevious: true)
|>fill(column: "_value_CO2meas", value: 400.00)
|> fill(column: "_value_Tmeas",usePrevious: true)
|>fill(column: "_value_Tmeas", value: 20.0)
second_join = join(tables: {first_join: first_join, Pmeas: Pmeas}, on: ["_time"])
|>fill(column: "_value", usePrevious: true)
|>fill(column: "_value", value: 1013.25)
|>map(fn: (r) => ({_time: r._time, _Pmeas: r._value, _CO2meas:r._value_CO2meas, _Tmeas:r._value_Tmeas}))
final = second_join
|>map(fn: (r) => ({Pmeas: r._Pmeas, CO2meas:r._CO2meas, Tmeas:r._Tmeas, Pref: Pref, Tref: Tref, _time: r._time,}))
|> keep(columns: ["_time", "CO2meas", "Pmeas", "Tmeas", "Pref", "Tref"])
CO2corr = final
|> map(fn: (r) => ({"_time": r._time, "CO2-Measured": r.CO2meas, "CO2-Adjusted": r.CO2meas * (((r.Tmeas + 273.15) * r.Pref) / (r.Pmeas * r.Tref))}))
|> yield()I did the same in WarpScript, with comments, which were lacking in the flux version:
// Assuming read token is in $RTOKEN
30 d 'duration' STORE // We want to process the last 30 days of data
NOW 'now' STORE // Store the current time
// fetch data from the database
[ $RTOKEN 'Tmeas' {} $now $duration ] FETCH 'Tmeas' STORE
[ $RTOKEN 'Pmeas' {} $now $duration ] FETCH 'Pmeas' STORE
[ $RTOKEN 'CO2meas' {} $now $duration ] FETCH 'CO2meas' STORE
// bucketize the series, using 30 s buckets and applying a mean
[ $Tmeas bucketizer.mean $now 30 s 0 ] BUCKETIZE 'Tmeas' STORE
[ $Pmeas bucketizer.mean $now 30 s 0 ] BUCKETIZE 'Pmeas' STORE
[ $CO2meas bucketizer.mean $now 30 s 0 ] BUCKETIZE 'CO2meas' STORE
// We now fill the gaps with the previous value, if any, or with default values
$Tmeas FILLPREVIOUS [ NaN NaN NaN 20.0 ] FILLVALUE 0 GET 'Tmeas' STORE
$Pmeas FILLPREVIOUS [ NaN NaN NaN 1013.25 ] FILLVALUE 0 GET 'Pmeas' STORE
$CO2meas FILLPREVIOUS [ NaN NaN NaN 400.0 ] FILLVALUE 0 GET 'CO2meas' STORE
// Now we compute the final result
298.15 1013.25 [ 'Tref' 'Pref' ] STORE
$Tmeas 273.15 + $Pref * $Pmeas $Tref * / $CO2meas * 'result' RENAME| What are the 4 stages of maturity of Industry 4.0? |
That's a direct translation of the flux code. I personally think filling each series with the previous point is not a good idea. If the CO2 sensor does not send any information, but temperature and pressure are still measured, the result will ultimately be false. It would be far better to compute the result only if all three data are available.
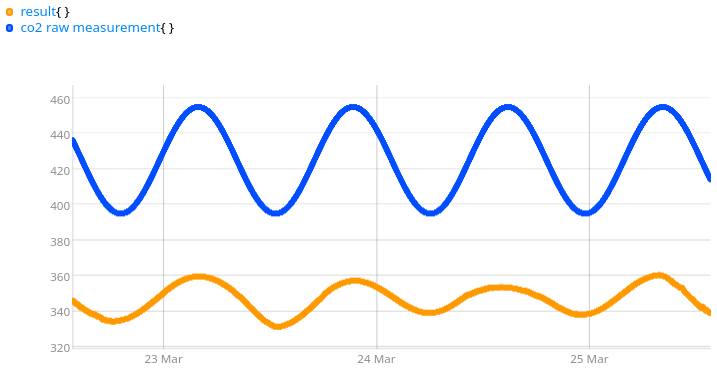
We will remove a few points in the CO2 data. With WarpScript, you remove a sublist of ticks among all the ticks:
$CO2meas $CO2meas TICKLIST [ 3000 6000 ] SUBLIST REMOVETICK 'CO2meas' STORE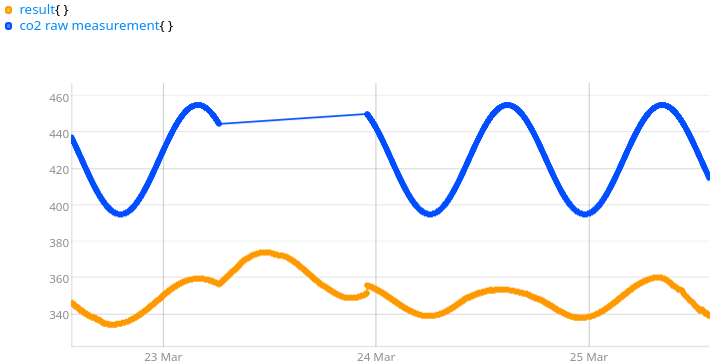
"It would be far better to compute the result only if all three data are available": In WarpScript, the function name is explicit: COMMONTICKS. It takes a list of Geo Time Series (GTS), and produces a list of GTS with only the ticks they have in common. So you build a list [ x y z ], call COMMONTICKS, deconstruct the list LIST-> and store each element of the list in their respective variables.
// Assuming read token is in $RTOKEN
30 d 'duration' STORE // We want to process last 30 days
NOW 'now' STORE // Store the current time
[ $Tmeas bucketizer.mean $now 30 s 0 ] BUCKETIZE 0 GET 'Tmeas' STORE
[ $Pmeas bucketizer.mean $now 30 s 0 ] BUCKETIZE 0 GET 'Pmeas' STORE
[ $CO2meas bucketizer.mean $now 30 s 0 ] BUCKETIZE 0 GET 'CO2meas' STORE
[ $Tmeas $Pmeas $CO2meas ] COMMONTICKS LIST-> [ 'Tmeas2' 'Pmeas2' 'CO2meas2' NULL ] STORE
// Now compute the final result
298.15 1013.25 [ 'Tref' 'Pref' ] STORE
$Tmeas2 273.15 + $Pref * $Pmeas2 $Tref * / $CO2meas2 * 'result with common ticks' RENAME
// We store the result in $result
DUP 'result' STOREThe result, in red below, is far less worrying:
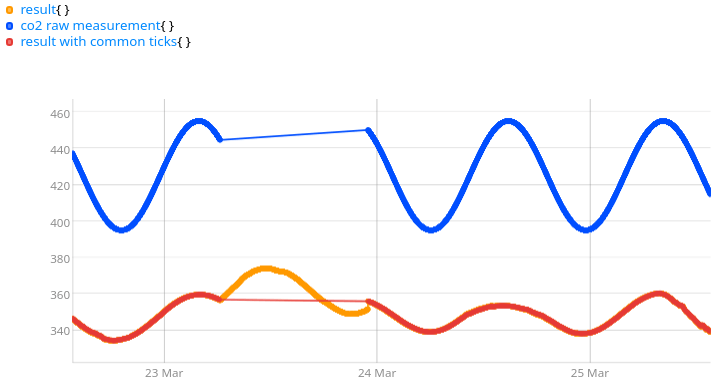
If you want to fill the result with the previous computed value, add the following line to the previous WarpScript:
[ $result bucketizer.mean $now 30 s 0 ] BUCKETIZE FILLPREVIOUSNot using Warp 10 or WarpScript yet? Do not give up hope! You can plug the Warp 10 analytics engine on top of an existing time series database. For InfluxDB, the open source plugin is here.
Read more
How does a time series correlates with its past?
Review of DELL compatible batteries using Warp 10
Warp 10 migration: is it complex?

Electronics engineer, fond of computer science, embedded solution developer.