Ouverture des données dans la Loi d"Orientation des Mobilités (LOM) : Nous prépare-t-elle véritablement à la transformation de la mobilité vers la multimodalité (Mobilité as a Service / MaaS) ?

La Loi d’Orientation des Mobilités (LOM) du 24 décembre 2019 accorde une large place à l’ouverture des données. L’objectif vise d’abord à favoriser l’accès des utilisateurs à des services plus riche en matière de transport. Il est aussi de faciliter l’échange de données entre acteurs de transport dans une perspective de mobilité globale que recouvre le concept de MaaS (Mobility as a Service).
La loi ouvre notamment l’accès aux données des offres de mobilité en temps réel. Les professionnels attendent les décrets d’applications, qui font encore l’objet d’âpres discussions et de lobbying de tous côtés. Sauf surprise qui viendrait contredire l’esprit de la loi, il s’agit d’une évolution notable de la situation préexistante. Les données accessibles de transport correspondaient, le plus souvent en effet, aux plans des lignes des réseaux et aux horaires.
Voir également Les données dynamiques au cœur des Smart cities et Les séries temporelles : le futur de la donnée
Mobilité : des services existants
Plusieurs services disponibles sur les smartphones n’ont cependant pas attendu la loi pour exercer une pression sur les opérateurs de transport. C’est le cas de CityMapper, Google ou Moovit. Ils proposent des services de calcul d’itinéraires en pouvant associer différents modes de déplacement. La RATP à Paris a autorisé l’accès à ses données en temps réel au début de l’année 2017. D’autres villes avaient anticipé cette évolution, comme Rennes dès 2010 ou encore Lyon en 2015.
La plupart des données temps réel disponibles correspondent au contenu des afficheurs et autres écrans mis en place depuis quelques années dans les stations. Ils permettent de renseigner les voyageurs sur l’heure du prochain passage d’un bus, d’un train… S’il s’agit bien d’une information disponible en temps réel, et non, bien au contraire, de l’information sur la position réelle d’un véhicule. Des villes se sont engagées dans cette dernière voie, comme Londres dès 2009 avec le système iBus.
De la mobilité vers l’intelligence artificielle
L’information en temps réel disponible, à savoir l’heure du prochain passage d’un véhicule de transport, peut, dans un premier temps, suffire pour calculer un parcours multimodal. Cependant, ce type d’information ne permet pas d’envisager de services qui, dans les années à venir, pourront reposer sur des modèles prédictifs avancés et, notamment, sur l’intelligence artificielle. Une telle orientation suppose, en effet, de mettre en œuvre des modèles d’apprentissage (Machine Learning) appliqués au suivi des flux des positions « Temps Réels » des modes de transport. Ces flux de données de géolocalisation constituent les données brutes qui seront aux cœur des services MaaS.
L’heure prévisionnelle de passage d’un bus, métro ou tramway à une station n’est précisément pas une donnée brute. Elle résulte d’un algorithme – le cas échéant propriétaire – d’un prestataire retenu à dessein. De ce fait, elle n’a que peu de valeur dans les modèles prédictifs multimodaux. Par ailleurs, il faut, pour obtenir cette donnée, envoyer une requête d’interrogation pour chaque station et environ une fois par minute (en tablant sur le fait que deux bus sur la même ligne ne vont pas s’arrêter à la même station dans cet intervalle d’une minute).
Les quelques exemples suivants sont autant d’illustrations d’analyses et de services qui auront de plus en plus besoin des données brutes :
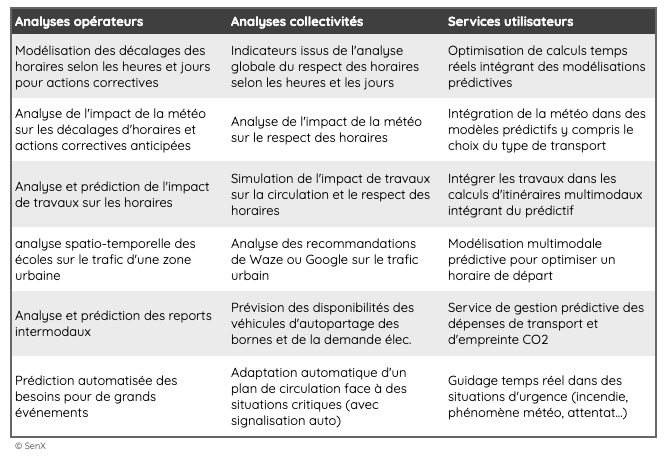
Ces différentes analyses et services seront impossibles sans un accès à des données brutes sur lesquelles appliquer des modèles d’apprentissage basés sur l’analyse des flux dans tous les types de situation.
Un changement radical des technologies de traitement des données
Il faut, aussi et surtout, disposer d’outils avancés pour tirer parti des historiques de données issues de sources différentes. Grâce à l’apport d’expert en Data Sciences, beaucoup de sociétés sont aujourd’hui en capacité de développer des modèles pouvant être adaptés à des usages spécifiques. C’est le cas pour la plupart des exemples listés dans le tableau ci-dessus, tant que les sources de données restent en nombre limité.
Cependant, peu de ces sociétés disposent d’outils pouvant intégrer à une large échelle, des sources de données de plus en plus nombreuses dans la mobilité. Celles-ci ont des formats très variés et ont des comportements à chaque fois différents. Les "Proofs of Concept" et autres "challenges" ont tendance à masquer cette véritable barrière que génère la multitude, la diversité et le volume des données ainsi produites.
Une solution open source
C’est tout l’enjeu de l’industrialisation du traitement des données qui doit en outre répondre à de fortes contraintes de sécurité. Warp 10, la solution Open Source développée par SenX a été précisément créée pour répondre à ces défis. Elle s’appuie pour ce faire, sur la technologie des séries temporelles.
Dans une approche de ce type, les données sont stockées, organisées et traitées à partir de cette simple clé d’entrée qui est le temps. Plus précisément l’horodatage. C’est la valeur commune à toutes les données séquencées.
Mobilité et données : un train de retard pour la loi LOM Share on XDans les systèmes informatiques classiques, les données sont structurées en fonction de contingences métiers avec des formats spécifiques à chaque environnement, à chaque acteur… Les techniques de séries temporelles empilent les données au fur et à mesure sans s’encombrer de formats spécifiques. Une donnée sera en effet de plus en plus utilisée par plusieurs métiers. Pourquoi dès lors figer un format de stockage qui va peser sur le potentiel d’usage des données ? Les techniques de séries temporelles sont par ailleurs, bien plus puissantes (jusqu’à un facteur pouvant dépasser le millier) pour les données de capteurs et autres mesures.
Plusieurs solutions existent aujourd’hui sur le marché des séries temporelles (Time Series). Point de différenciation, Warp 10 intègre la géolocalisation dans la structure de base de son architecture. On parlera ainsi de séries spatio-temporelles (Geo Time Series), lesquelles trouvent dans les données de mobilité, un champ d’application sans limites.
La nécessaire constitution d’historiques de données de mobilité
Les données de mobilité ont en effet toutes ce point commun d’être à la fois séquencées dans le temps et géolocalisées. Warp 10 offre de fait, un ensemble de fonctions sur étagère, directement exploitables pour des applications et des services de mobilité.
Comme déjà évoqué précédemment, l’une des voies les plus prometteuses pour Warp 10 est celle de l’intelligence artificielle. Non pas pour apporter des solutions toutes faites, ce qui n’aurait pas de sens, mais comme un outil qui va être en mesure de créer les conditions d’extraction de la valeur de la donnée. Warp 10 sera ce qu’on appelle un "Artificial Intelligence enabler".
Les usages les plus connus de l’IA s’appuient sur l’apprentissage sur des contenus multimédia : reconnaissance d’un texte, d’un langage, d’un chien sur une photo, d’une table, d’une voiture, d’un visage sur une image ou une vidéo).
Dans le cas de Warp 10, on s’intéresse à un autre type d’apprentissage qui porte sur des mesures séquencées dans le temps et, selon le cas, géolocalisées. Il s’agit alors de comprendre avec une suite de multiples mesures comment fonctionne un moteur, une voiture, le trafic automobile… ou encore la santé d’un individu pour par exemple, anticiper ses défaillances.
Historiques de données
Ce travail sur des sources de données séquencées dans le temps nécessite l’accès à des historiques des données. Dans le secteur de la mobilité où interviennent des problématiques de saisonnalité, ce seront des années d’historiques qu’il conviendra de conserver. Sans l’accès à de telles données, il est vain de vouloir développer des services basés sur l’intelligence artificielle.
On ajoutera que ce constat conduit les collectivités à faire face à deux injonctions paradoxales. D’un côté, et pour des raisons diverses comme la protection de la vie privée, elles ne peuvent collecter des données que lorsque des cas d’usages sont clairement définis. De l’autre, il leur est demandé de développer ou de favoriser le développement de nouveaux services qui vont de plus en plus, nécessiter l’accès à un historique de données dont elles ne disposent pas.

La quête des sources de données
D’un point de vue technique, il existe plusieurs façons de récupérer des données brutes de mobilité.
- À partir des moyens de transport lorsque ceux-ci sont équipés de systèmes de localisation connectés (trackers). Cela s’applique aux transports publics, et le cas échéant aux voitures, vélos, scooters ou autres trottinettes en mode partagé.
- À partir d’une application fonctionnant en arrière-plan sur un smartphone. Cela peut être le cas avec Google Maps, Waze, Here, CityMapper, Moovit… mais aussi RATP, ViaNavigo ou encore des acteurs indépendants tels ZenBus. C’est aussi le cas pour les applications de partage de véhicule, de scooter et trottinettes qui différencient les données du véhicule et celles de l’utilisateur.
- À partir d’un téléphone portable quelconque localisé en permanence par l’opérateur de télécommunications.
Le recours à ces techniques pose des questions plus ou moins aiguës en termes de protection de la vie privée. Contrairement à une application ayant sollicité le consentement de l’utilisateur, l’opérateur téléphonique n’en dispose pas de manière explicite. Dans le cas du tracker de véhicule, l’information n’est pas directement une information personnelle, même si cette distinction devient plus compliquée pour les véhicules personnels.
L’analyse des données de mobilité peut cependant recourir à une anonymisation des données. Au-delà de l’identification, il faut aussi ajouter une notion de « floutage » géographique des origines et destinations pour éviter un risque de localisation précise qui reviendrait à identifier indirectement un utilisateur.
Volumes de données
En admettant que ces difficultés soient résolues, vient le temps de traitement des données avec des positions temps réel et leur historique qu’il va falloir ingérer, stocker et analyser. Il ne s’agit pas ici de simples statistiques, mais de calculs avancés tels ceux données en exemple dans le tableau présenté ci-dessous.
Le réseau francilien
Prenons l’exemple des transports publics à Paris, les plus denses en France. Le réseau RATP se compose d’environ 5000 autobus et de plus de 700 rames de métro. En supposant que la position GPS soit générée une fois par seconde, même à l’arrêt au dépôt (ce qui est une information potentiellement intéressante), on obtient un total de 500 millions de mesures par jour.
Supposons que tous les voyageurs soient équipés d’un smartphone, sachant que le trafic de la RATP est d’environ 3,5 milliards de voyages par an. On considère que la durée moyenne d’un voyage est de 45 minutes, et qu’une position est générée une fois par seconde (Sur une base empirique de 18 heures de production par jour). On obtient le chiffre théorique proche de 10 000 milliards de mesures par an. Soit environ 25 milliards de mesures par jour ou encore autour de 400 000 mesures par seconde (sur une base empirique de 18 heures de production par jour).
Pour comparaison, les réseaux de Lyon (TCL) et de Marseille (RTM) assurent respectivement 500 millions et 310 millions de voyages par. Soit un potentiel de mesures qui, sans calcul plus approfondi, serait respectivement inférieur de 7 à 10 fois celui de Paris.
Un volume global important, mais pas colossal
L’ensemble des réseaux de transport public en France représente environ 3 milliards de voyages selon l’Observatoire de la mobilité de l’UTP. Avec des durées de déplacement un peu moindres en province, on obtient un total national de 15 000 milliards de mesures par an. Ce qui fait 40 milliards de mesures par jour ou encore 630 000 mesures par seconde (sur une base empirique de 18 heures de production par jour).
Pour une vision plus exhaustive il faut ajouter le réseau ferroviaire francilien (transilien), soit un peu moins de 1 milliard de voyages par an, les autres réseaux ferroviaires régionaux (TER) et les réseaux de bus de la région parisienne hors RATP (réseaux OPTILE). Sous réserve de calcul plus précis, le nombre de mesures par seconde pour un suivi des voyageurs serait de l’ordre de 1 million de mesures par seconde. Soit 65 milliards de mesures par jour ou 24 000 milliards de mesures par an.
Ces nombres sont considérables pour les systèmes et applications informatiques opérationnels au sein des entreprises de transport. Ces derniers sont généralement calés sur la billettique. Les 3,5 milliards de voyages de la RATP correspondent ainsi à 150 opérations par seconde, volume finalement modéré dans l’univers du Big Data.

L’entrisme de Google et des acteurs du numérique
Dans l’univers du Big Data et de Warp 10, le traitement et le stockage historisé de 1 million de mesures par seconde n’est absolument pas démesuré. Le nombre de mesures collectées par un avion ou pour le monitoring d’un data center peut être bien supérieur à un tel chiffre. On est aussi très loin de la capacité des acteurs du numérique comme Google ou Waze.
Google Maps est ainsi utilisé par 1 milliard d’individus. À supposer que la moitié accepte le suivi de leurs déplacements, le total frise 100 millions de mesures de géolocalisation en continu par seconde (hypothèse empirique d’un suivi des déplacements d’un utilisateur sur un peu moins de 2 heures par jour avec un relevé par seconde).
Les opérateurs de télécommunication ont aussi développé des plateformes qui leur permettent d’analyser les déplacements des utilisateurs de mobiles. C’est le cas par exemple d’Orange, avec le service FluxVision. Positionnés sur les analyses de mobilités, les telcos sont confrontés, plus que Google et d’autres, à des risques plus importants en matière de protection de la vie privé. Ceci est dû à l’absence de consentement explicite.
La controverse de Toronto et l’entrisme de Google dans l’urbanisme et la mobilité
Google a racheté en 2016 la société Urban Engines spécialisée sur les données de mobilité. Combinée avec la richesse des données collectées par Google, cette expertise a été intégrée dans l’offre Sidewalk Labs. Celle-ci s’est trouvée au cœur de la controverse née du projet proposé clé en main à la ville de Toronto. Lauréat d’un appel d’offres pour le réaménagement d’un quartier, le projet de Google entend faire le lien entre urbanisme et Smart City. Une polémique s’est développée sur le traitement des données jusqu’à prendre une dimension internationale. Plusieurs amendements ont été apportés et le marché qui apparaissait en situation difficile en 2019, était en voie de se conclure au printemps 2020. La crise sanitaire actuelle vient cependant de conduire Google à se retirer du projet au grand regret du maire de Toronto.
D’autres villes ont succombé aux charmes de Sidewalk Labs dès lors que Google leur a proposé de rémunérer leurs données publiques. Civiteo qui suit particulièrement ce sujet a été sollicité par Google, mais a préféré décliner l’offre de test en France. Le groupe français Colas, filiale de Bouygues, a de son côté signé un accord avec Sidewalk Labs.
Si Google est à la pointe de cette évolution, de nombreux acteurs du numérique et de la mobilité entendent suivre le mouvement. Ils s’engagent dans la collecte et le traitement des données dans la perspective de l’explosion des services MaaS, un marché qui devrait croître de 31 % par an pour atteindre 107 $ milliards à en 2030. Waze, Uber, Here, Lyft, Trafi, ReachNow, BMW ou Daimler sont déjà sur les rangs…
La LOM : le biais de l’open data
En synthèse, il faut retenir six points importants :
- Le développement des services MaaS va faire appel de manière croissante aux données temps réel avec une tendance à l’accès à la position des véhicules.
- Le développement des applications et services pouvant tirer profit de l’intelligence artificielle nécessitera de stocker et de traiter de grands historiques de données pour pouvoir faire de l’apprentissage temporel.
- Les opérateurs de transport n’ont plus l’exclusivité des données avec des sources de données qui se multiplient au travers du développement des services sur mobile.
- Le traitement des volumes de données donne lieu à une rupture technologique à laquelle les acteurs traditionnels du transport ne sont pas préparés.
- Ces mêmes volumes, importants pour les acteurs traditionnels du transport, sont relativement faibles par rapport aux capacités de traitement des grands acteurs du numérique.
- Les perspectives de développement du marché du MaaS excitent les appétits d’entreprises qui, à l’instar de Google, ne veulent pas dépendre des acteurs de transport.
Une loi qui favorise l’ouverture des données de mobilité, mais…
Dans ce contexte, la Loi d’Orientation des Mobilités va dans le sens de l’histoire. Elle repose sur l’idée que l’ouverture des données, et notamment des données temps réel des opérateurs de transport, va permettre de développer des services de mobilité multimodale. Ce faisant, elle entend favoriser le développement de services qui vont contrer les ambitions des grands acteurs du numérique et notamment de Google. Or cette stratégie n’est pas pertinente, et ce, pour au moins cinq raisons.
- Pour des raisons de sécurité, de protection de la vie privée, de protection de données protégées par des droits connexes… Les données ouvertes resteront nécessairement limitées. Certes, les opérateurs de transport devront donner l’accès à des données dynamiques. Mais celles-ci pourront résulter de traitements et ne seront pas les données brutes dont les acteurs de services auront besoin.
- Cette orientation basée sur les données ouvertes conduit les acteurs à se tromper de débat. La question n’est pas de savoir comment on ouvre les données et comment on passe son temps à limiter cette ouverture. Elle devrait être de croiser des données brutes d’acteurs différents et, le cas échéant concurrents, de manière protégée et sécurisée sans qu’ils aient pour cela besoin d’accéder aux données brutes elles-mêmes.
- La limitation du débat aux données ouvertes n’encourage pas les collectivités – et leurs fournisseurs – à franchir le saut technologique du Big Data. Elles confient souvent l’ouverture des données à un tiers alors que le territoire intelligent de demain va générer des données brutes en très grands volumes qui seront au cœur de leurs propres services.
- Les grands acteurs du numérique savent parfaitement que les nouveaux services de mobilité ne seront pas basés sur les données ouvertes, mais sur l’agrégation de données brutes les plus exhaustives possibles.
- Les grands acteurs du numérique seront en capacité de mieux tirer profit des données ouvertes en permettant d’affiner leurs propres données. Ce faisant, ils tueront toute nouvelle valeur que des acteurs alternatifs pourraient vouloir créer.
Une automatisation indispensable
Beaucoup de collectivités, tout comme l’État, ont été sensibilisées positivement à la question de la gouvernance des données. Cependant, ce débat masque totalement la prise de conscience nécessaire des enjeux technologiques. Ces derniers apparaissent comme totalement secondaires parce que perçues comme un non-problème. Or le passage à l’échelle et la nécessaire automatisation des analyses de données constituent des défis technologiques. Ainsi en mode opérationnel, on ne transmet pas les données à un data scientist qui renvoie les résultats quelques heures après. L’analyse et l’interprétation des résultats doit être intégrée dans des processus automatiques.
Ces contraintes qui paraissent des évidences, imposent de maîtriser les techniques et outils qui relèvent, non pas de la science de la donnée (Data Science) mais de l’ingénierie de la donnée (Data Engineering). Les deux niveaux s’opposent encore trop souvent et les « Data Scientists » n’ont souvent que faire des contraintes techniques qu’entendent traiter les « Data Engineer ». Tout cela fait l’affaire des grands acteurs du numérique dont la capacité technique apparaît le moment venu comme incontournable. C’est pour partie ce qui s’est passé avec les données de santé où Microsoft a été retenu dans un contexte houleux, pour opérer le Health Data Hub après des années passées à débattre sur la gouvernance.
Le risque que le débat sur les données mobilité se termine de la même manière est loin d’être négligeable. On peut même estimer à l’heure actuelle que c’est le scénario le plus probable.
Vers la création d’une infrastructure de données neutre et sécurisée
Avec Warp 10, SenX s’active à promouvoir la création d’infrastructures de données neutres sans prétention aucune en matière de création de services de mobilité. Une telle option ne consiste pas à simplement agréger des données et à en donner l’accès à quiconque. Elle met des outils de gouvernance des données dans les mains des acteurs – sans préjuger des règles qu’ils définiront – et donne la possibilité de croiser des sources de données variées, hétérogènes, nombreuses. Un acteur pourra alors avoir accès, selon ses droits, à des données temps réels, ou agrégées à l’heure ou la journée, ou agrégées selon un périmètre géographique, ou résultant d’un traitement … Toute cette souplesse repose sur des mécanismes et outils de traitement de séries spatio-temporelles qui vont jouer un rôle majeur dans le développement des services de mobilité.
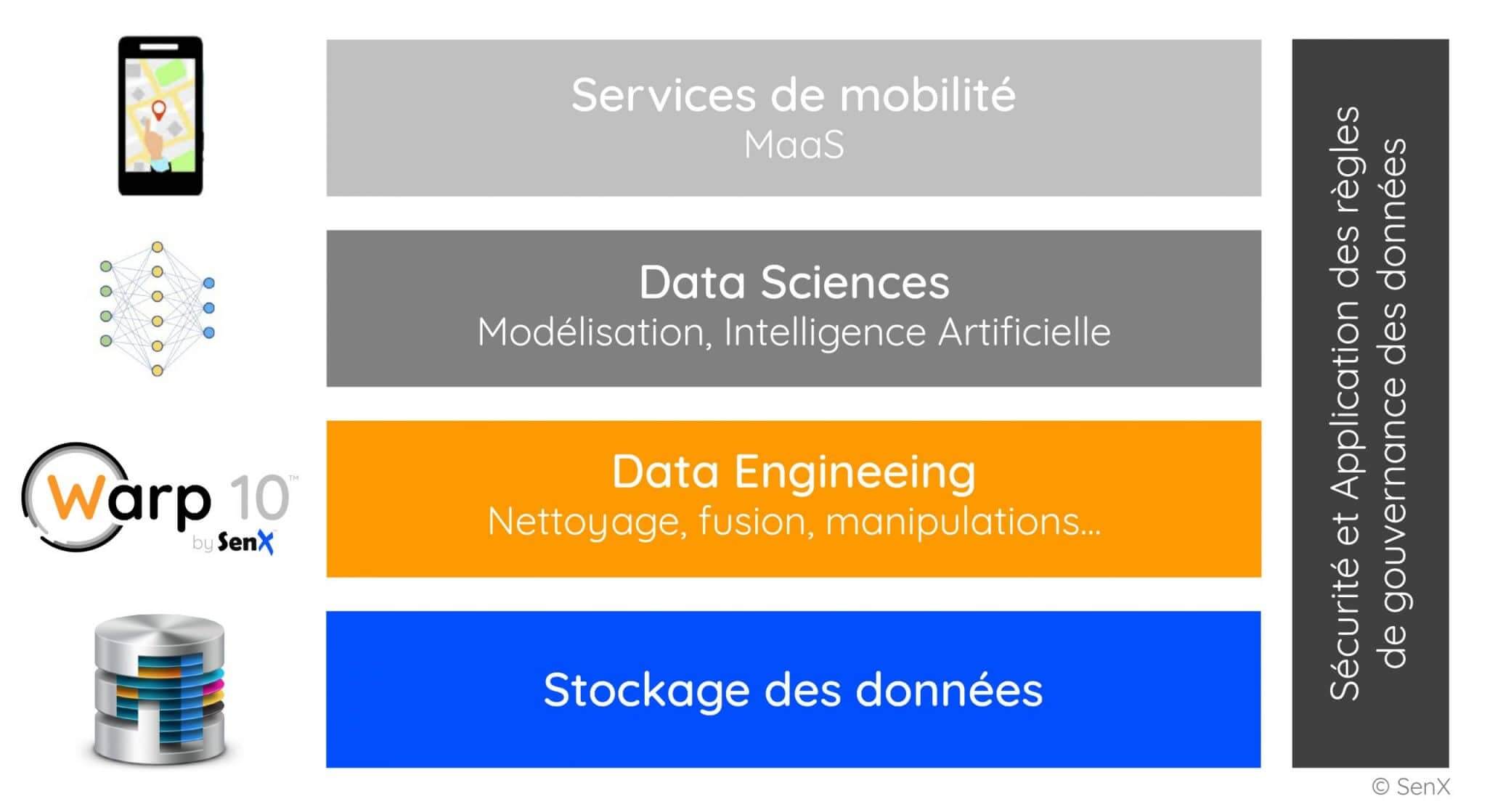
Les acteurs de la mobilité ont des réticences sur la question l’accès aux données telle que prévue par la LOM. On peut les comprendre dans la mesure où le biais sur l’ouverture des données alimente le sentiment qu’on ouvre la boîte de Pandore et que tout sera demain ouvert. Or le vrai sujet, c’est le big data dont l’open data n’est qu’un sous ensemble. La question est bien d’imaginer les infrastructures, les mécanismes et les règles qui vont demain ouvrir le jeu en respectant les prérogatives de chacun, condition incontournable pour que chacun à sa place, devienne acteur du changement.
Nous aborderons dans un autre papier la relation nouvelle que cette évolution va induire entre les opérateurs et les collectivités territoriales. Celle-ci va changer de nature et le big data va en être le moteur. On ne perçoit encore que les prémisses de cette évolution.
Vous avez des questions sur les séries temporelles et le stockage des données ? Contactez SenX : contact@senx.io
Read more
Working with GEOSHAPEs: code contest results
WarpScript 101: About the syntax
Données des objets connectés de santé : changer de braquet
Co-Founder & former CEO of SenX