Les architectures et techniques de traitement de données vivent une révolution avec le fort développement des séries temporelles (Time Series)
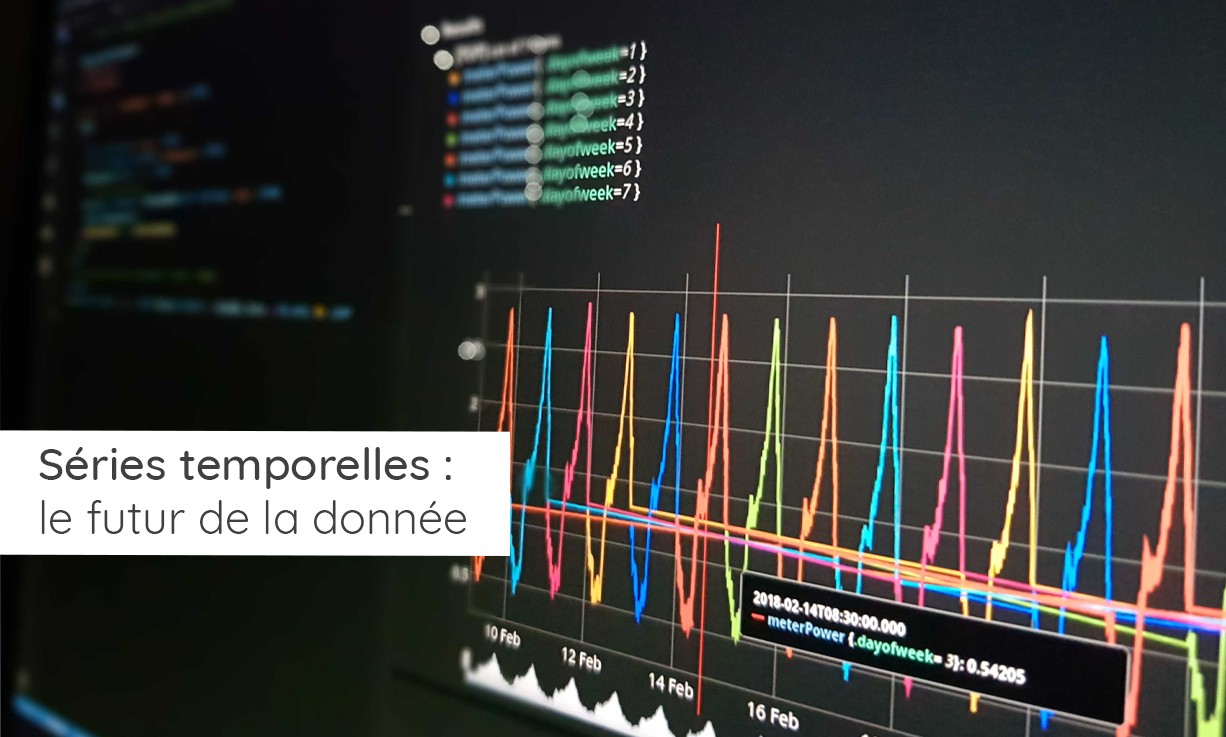
Partant des besoins de traitement de données pour le monde des capteurs et de l’internet des objets, SenX a développé une solution logicielle dénommée Warp 10. Distribué en Open Source, Warp 10 est basé sur un mode d’organisation des données connu sous le nom de « séries temporelles » (ou « séries spatio-temporelles » lorsque la localisation est disponible).
Cette rupture technologique apparaît alors que l’avènement du Big Data et du « tout connecté » impose de repenser radicalement l’organisation de nos systèmes d’information.
Cet article est également disponible en anglais.
Les systèmes d’information existants peu adaptés à la transformation numérique
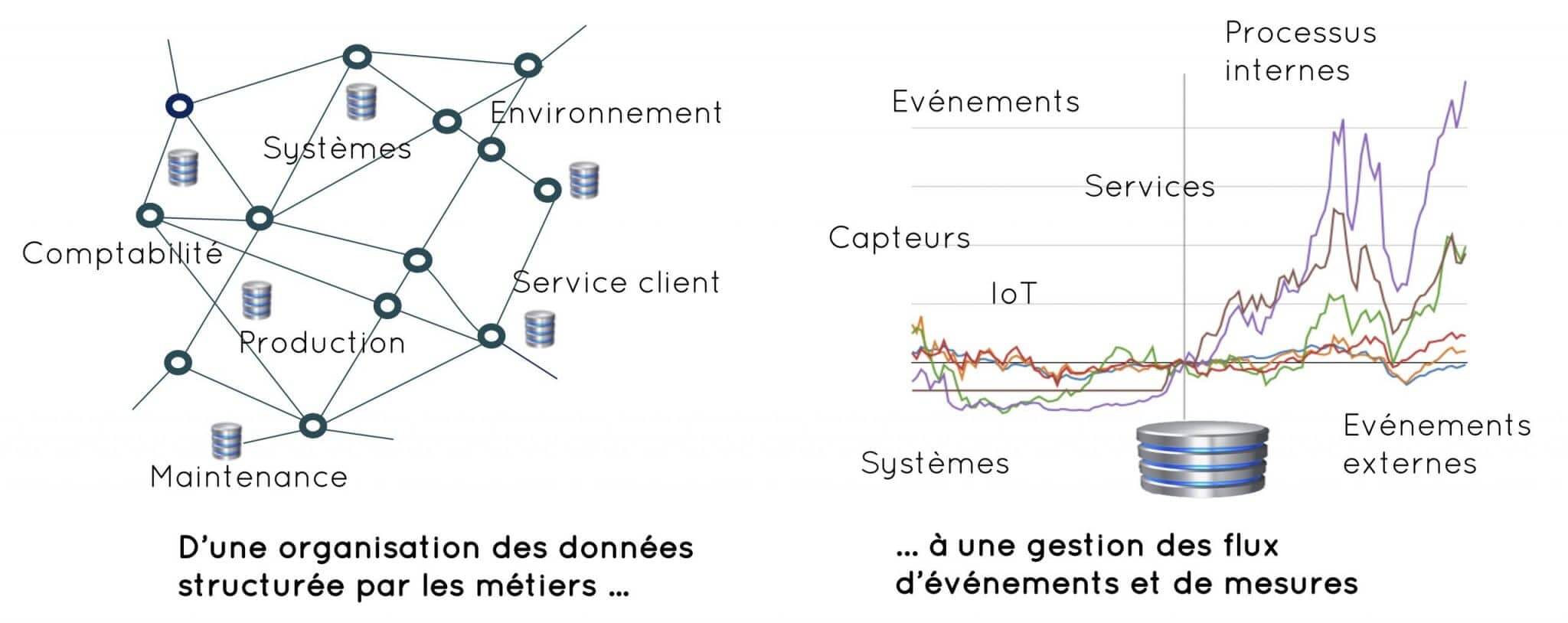
Au sein des organisations, les données sont généralement gérées dans de grandes bases dites « relationnelles ». Celles-ci sont communément appelées bases de données structurées (ou bases SQL pour Structured Query Language). Issues d’applications métiers (finances, achat, ventes, production …), leur organisation s’appuie sur des formats et une sémantique propre à chaque métier ou domaine d’activité.
La structuration des données par application métier débouche sur une organisation en silos. La DSI en assure la cohérence en s’appuyant généralement sur un socle technologique commun.
Depuis plus de vingt ans, les organisations publiques ou privées recourent à des technologies d’analyse décisionnelle (« Business Intelligence », BI) dans un souci d’une meilleure gestion. Les outils de BI vont ainsi fouiller, et le cas échéant croiser et fusionner des données produites par différentes applications métiers (comptabilité, personnel, gestion des actifs, production opérationnelle, trafics…).
Ces technologies ont façonné des systèmes d’information à deux étages. En amont des applications métiers verticales tournées vers les usages (qui répondent aux fonctions centrales des organisations). En aval, des projets « horizontaux » qui doivent à la fois rationaliser et faciliter le développement et l’exploitation opérationnelle de nouveaux services.
L’émergence du Big Data et de ses promesses a accentué la pression à l’égard des DSI. Ils doivent désormais répondre aux besoins de nouveaux services reposant sur une exploitation de plus en plus dynamique des données.
La structuration usuelle des données fait obstacle aux usages multiples de la donnée
Alors que la donnée était avant tout liée à une fonction métier, la tendance tend à en diversifier ses usages non plus pour une seule application, mais pour plusieurs. Par ailleurs les organisations sont de plus en plus tournées vers leurs clients ou vers les citoyens. Ainsi les données qui avaient avant tout un usage interne alimentent de nouvelles gammes de services.
Elles vont ainsi répondre à des usages potentiels qui n’apparaîtront qu’au fil du temps. De plus, alors que les applications de type BI pouvaient s’appuyer sur des données extraites une fois par jour des applications métiers, de plus en plus de services s’appuient sur des données tendant vers le temps réel.
Les bases de données classiques sont peu adaptées à cette évolution pour 5 raisons essentielles :
- La propriété : alors que les données constituent en théorie un actif d’une organisation, c’est en réalité chaque direction qui se considère comme propriétaire de ses données.
- L’interopérabilité : chaque direction gère ses données au travers de formats spécifiques à chaque métier. Les standards qui représentent autant de chapelles ne sont que peu appliqués sans compter qu’ils sont souvent à la traîne des innovations.
- Les performances : la lourdeur des technologies existantes tient notamment à la structuration des données, aux mécanismes relationnels entre les données et aux contraintes d’intégrité dans leur mise à jour. Pour ne pas dégrader les applications métiers, elle impose d’effectuer des extractions dédiées dès lors que les données doivent être mises à disposition pour de nouvelles applications. Elles qui ne peuvent se faire que dans des périodes non contraintes comme la nuit.
- La perte d’informations : les applications métiers initiales ne conservent que les informations qu’elles jugent pertinentes. Cela conduit à perdre des données que d’autres services auraient pu utiliser.
- Le manque d’évolutivité : l’évolution incessante des sources de données impose des remises à plat perpétuelles des structures des bases de données.
Dans les cas d’applications de gestion les plus courantes, ces obstacles n’en sont pas véritablement. Chaque silo étant relativement indépendant et traité en fonction de ses propres contraintes. Mais la priorité n’est plus celle-là. Elle est de trouver dans les données, une nouvelle source de valeur basée sur de nouveaux services.
Les séries temporelles : un vecteur de disruption dans l’organisation des données
Conçues au départ pour les données de capteurs, les bases à séries temporelles doivent faire face à des flux variés, nombreux, erratiques et le cas échéant très denses issus de sources très variées. Les applications métiers ne sont pas pensées au travers de la mise à jour d’une base de données, mais de la constitution d’un historique des flux.
Warp 10 est ainsi capable de traiter pour certaines applications, des flux de seulement quelques données par heure et pour d’autres, des flux de plus de 100 millions de mesures par seconde. Tout en garantissant dans le même temps de hautes performances d’accès et d’analyse.
Dès lors, au-delà des données de capteurs, on se rend compte qu’il n’y a qu’un pas pour ramener tout ce qui est opérationnel à des flux d’événements unitaires. Les voitures, les trains, les avions, les centrales électriques, les compteurs électriques, les systèmes de diagnostic ou de suivi médical, les infrastructures de télécommunications, les mobiles… Dans tous les systèmes et les processus, on passe d’un système de gestion de données formatées et gérées en silos à une gestion d’un flux de données brutes dont l’usage peut être multiple.
Par analogie, on peut considérer la tenue d’un compte bancaire
La base de données des comptes clients a toujours constitué un élément central du système d’information d’une banque. On a progressivement développé des outils d’analyse pour du scoring, de l’analyse de risque… en s’appuyant sur des extractions des mouvements sur le compte client. À bien y réfléchir aujourd’hui, c’est l’inverse qu’il faudrait faire avec les technologies dont nous disposons. Pourquoi en effet ne pas constituer un datalake des données brutes qui concernent l’ensemble des actions clients ? On pourrait y mettre aussi bien les actions ou opérations sur différents comptes, les informations d’accès et de navigation sur le portail internet… Il n’y aurait alors aucune difficulté à alimenter en parallèle les différentes applications dont la gestion de compte, la gestion de risque…
Téléchargez le guide pour le choix d’une base de données de séries temporelles
C’est bien l’ensemble des processus techniques et des activités humaines qui peuvent désormais être appréhendés comme une succession d’événements unitaires dans le temps : le fonctionnement interne à un système quelconque (mécanique, électrique, électronique, logiciel), aussi bien que les processus techniques et opérationnels ou la logistique.
Ce faisant, en ramenant toutes les données au temps, il devient possible de croiser des flux de données hétérogènes de manière bien plus aisée que dans des systèmes d’information classiques. Tout se ramène à des problèmes mathématiques de traitement de signaux, avec un résultat qui peut être interprété par une application métier comme elle l’entend. Encore convient-il de disposer des outils adaptés à ce type de traitement.
Performance, ouverture et flexibilité de l’approche qui est celle adoptée par Warp 10
Les barrières évoquées dans une approche classique en silos, sont en très grande partie levées par Warp 10 :
- Propriété : la priorité accordée aux données brutes atténue les crispations en matière de propriété
- Interopérabilité : les séries temporelles et spatio-temporelles fonctionnent sur un format universel basé sur le temps (et la localisation lorsque cela est pertinent), quitte à s’interfacer avec chaque métier en s’appuyant alors sur ses propres standards
- Performances : les hautes performances des bases à séries temporelles sont leur raison d’être
- Pas de perte d’information. On conserve tout, y compris des données erronées qui méritent examen
- Évolutivité : toute nouvelle source de données peut être intégrée facilement avec une fusion qui s’opère sur une échelle temporelle.
Cette évolution vers les séries temporelles est celle de la migration du monde des transactions vers celui des flux.
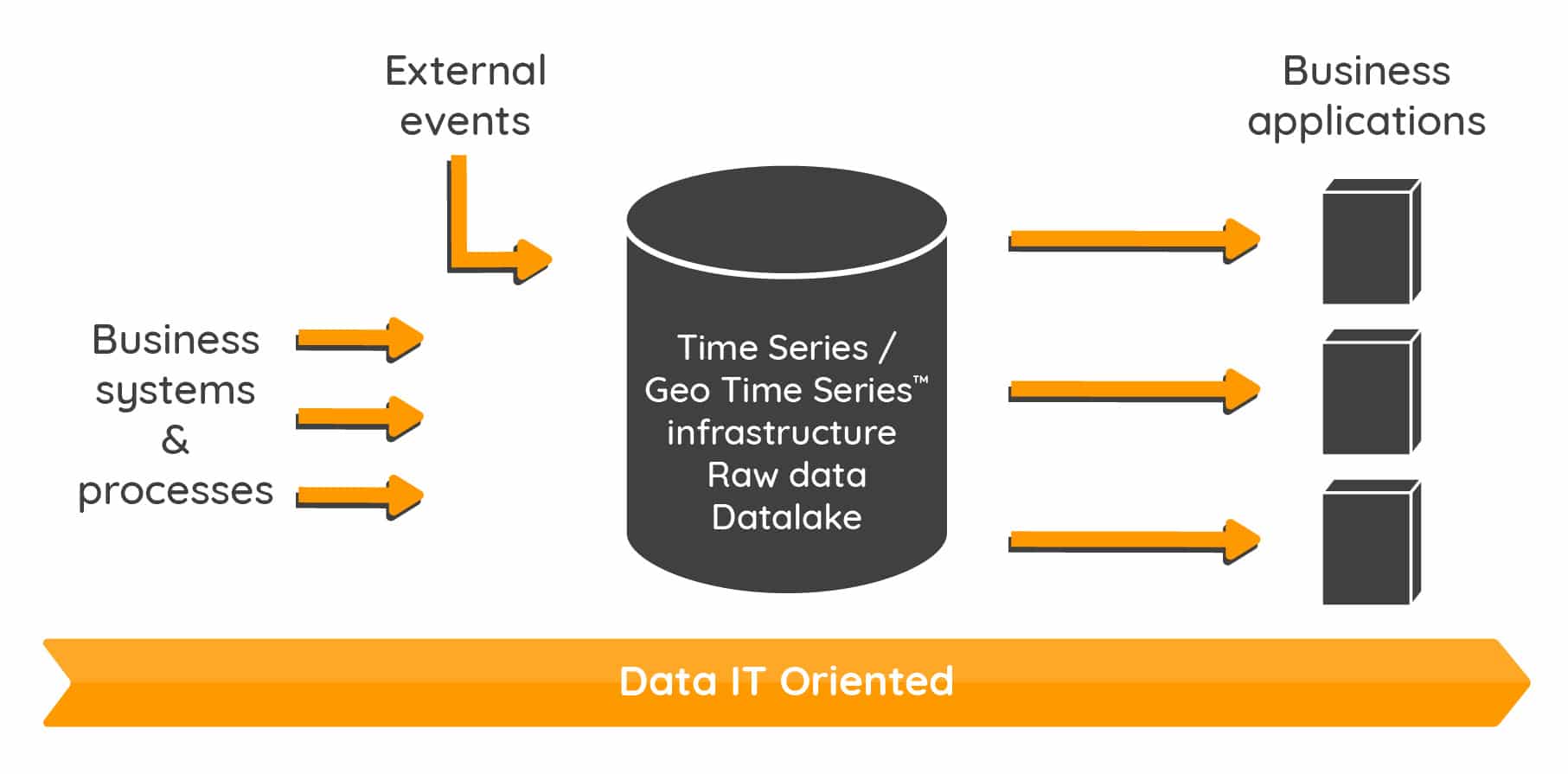
Warp 10 propose à cette fin une librairie de fonctions et d’algorithmes transversaux : socle d’une « infrastructure intelligente de données ». Cette infrastructure valorise l’importance de la donnée brute qui permettra l’explosion des applications pour aujourd’hui et pour demain.
La donnée brute est véritablement l’actif de chaque organisation. C’est à partir d’elle qu’on peut concevoir avec souplesse le développement de nouveaux services et applications sans être tributaire de telle ou telle application métier qui se serait appropriée la donnée. Ce faisant, on réduit grandement les problèmes d’interopérabilité qui sont pour grande partie liés précisément aux applications qui imposent leurs formats métiers.
Il faut surtout dans la constitution d’un tel actif, que s’impose l’idée d’enregistrer et donc d’historiser les données brutes. Ne pas le faire dès aujourd’hui, c’est réduire fortement le potentiel des applications et des services qui pourraient demain tirer profit des mécanismes d’apprentissage et d’intelligence artificielle.
On notera que les architectures de type séries temporelles sont celles qui connaissent aujourd’hui la plus forte croissance dans les techniques de gestion des données.
Des cas d’usage qui se multiplient
Parmi les secteurs les plus avancés des séries temporelles, on trouve :
- L’industrie. Les capteurs se multiplient aussi bien sur les systèmes de production et sur leur environnement, que sur les produits qui sont conçus afin de favoriser le suivi de leur fonctionnement opérationnel.
- L’aéronautique. Les nouveaux avions sont équipés de plusieurs centaines de milliers de capteurs dont certains produisent des centaines de mesures par seconde.
- L’énergie. Ce secteur fait face à la croissance des énergies renouvelables. Celles-ci sont instables alors que le réseau doit sans cesse s’autoréguler pour équilibrer la production et la consommation.
- La santé. D’un côté des équipements très pointus qui produisent des mesures dont l’exploitation des données historiques apporte un réel plus sur la compréhension de l’évolution d’un patient. De l’autre, des données de santé publique qu’il devient possible de croiser plus facilement comme le suivi des pathologies, la propagation d’un virus, les prescriptions, des parcours des patients, les actes…
- La mobilité. Elle s’appuie sur de sources de données toujours plus nombreuses qu’il faut croiser pour optimiser le trafic, les parcours collectifs et les itinéraires individuels. Le développement des services MaaS (Mobility as a Service) ne pourra se faire que sur la base de technologies Time Series.
- Les télécommunications. Les mobiles produisent notamment des volumes de données considérables à l’échelle du volume de ses utilisateurs.
- Le monitoring des infrastructures informatiques et réseaux. Un secteur qui permet la détection de signaux faibles entre des composants sans liens apparents et la maintenance prédictive.
- La ville intelligente (smart cities). Elle voit les sources de données se multiplier avec la modernisation des infrastructures et des services publics,
- La Défense. Les données temps réel ont toujours eu une importance particulière dans les systèmes de défense, les systèmes d’information et de commandement, la sécurité et la cybersécurité… Les nouvelles générations de capteurs donnent une nouvelle dimension à la problématique des données.
Il faudrait ajouter d’autres secteurs comme l’assurance, le sport, la logistique, les banques, l’agriculture amont (production) et aval (distribution)…
Data engineering et séries temporelles
Beaucoup d’entreprises et collectivités sont encore en phase exploratoire en matière d’exploitation des données et notamment des données de capteurs et autres IoT. Le data scientist est alors celui qui, par sa créativité et son savoir faire en matière de modélisation, va faire ressortir des résultats probants sur des cas d’usages. C’est le mouton à cinq pattes que le marché s’arrache.
Mais il y un monde entre l’expérimentation sur un cas d’usage et la mise en œuvre opérationnelle. Les contraintes sont alors celles du monde réel. Les sources de données sont plus nombreuses, diversifiées, hétérogènes et doivent faire face à problématiques de performance, de sécurité et d’administration des données. C’est là qu’intervient l’ingénierie de la donnée.
Ces deux activités que sont la science de la donnée (Data Sciences) et l’ingénierie (Data Engineering) ont vocation à se combiner. C’est loin d’être le cas. On demande trop souvent au data scientist d’être un architecte de la donnée qu’il n’est pas. On lira avec intérêt le papier de O'Reilly qui souligne les différences entre les deux approches et profils. Il faut trouver dans le manque de maturité des entreprises en matière de data engineering, l’une des explications de la difficulté de passer des POCs (Proofs of Concepts) à des applications véritablement opérationnelles.
La vision de SenX
SenX porte une vision originale sur le futur de la donnée en considérant que beaucoup d’entre elles seront traitées comme des séries temporelles et spatio-temporelles. Cette vision repose sur le constat d’une place croissante qu’occuperont les données dynamiques (donc temporalisées) et la nécessité pour les organisations de constituer des data lakes de données brutes. Quel index le plus neutre et plus universel que le temps (l’horodatage) pour suivre une telle voie ?
Warp 10 est précisément une solution qui s’inscrit dans cette vision qui vise à des traitements répondant à des enjeux de performance, de scalabilité, d’interopérabilité, de sécurité et d’industrialisation. Ce sont là les cinq conditions qui permettront le passage à l’échelle des applications qui sauront tirer parti de la richesse des données.
Pour conclure
Nous explorons à partir de cet article, plusieurs secteurs qui vont être exposés à l’explosion des données brutes "temps réel" et où le développement des séries temporelles et spatio-temporelles va s’imposer (Smart Cities, Mobilité, Energie, Santé …). Chacun des secteurs donnera lieu à un article dédié.
Si vous souhaitez un développement sur un secteur en particulier ou si vous avez des questions sur le contenu de cet article, contactez SenX : contact@senx.io
Read more
Spatio Temporal Indexing in Warp 10
Warp 10 scheduler secrets
When do you need a Time Series DataBase?
Co-Founder & former CEO of SenX