Les séries temporelles offrent une nouvelle approche qui peut simplifier la gestion des données de santé, laquelle résulte aujourd'hui d'un empilement historique de strates et de silos.

Le présent papier s’inscrit dans une série d’articles sur la manière dont les séries temporelles revisitent le mode d’organisation des données et les technologies utilisées pour leur analyse. Après un premier article de portée générale (Les séries temporelles : le futur de la donnée), les suivants abordent différents secteurs dont ici le secteur de la santé couvert par trois articles différents.
De la carte vitale au suivi de l’historique des actes, des analyses faites par un laboratoire au diagnostic, de l’appareillage perfectionné d’un hôpital à l’objet connecté à un smartphone… Tout ce qui concerne notre santé se traduit par des données qu’il faut stocker, traiter et naturellement protéger. Plus que toutes autres, les données de santé s’invitent au cœur des débats sur la protection de la vie privée.
Cet article vise à apporter un nouvel éclairage sur le traitement des données de santé par un intervenant dans un secteur dont il n’est pas spécialiste. SenX est un éditeur logiciel qui propose une solution technologique open source, Warp 10. Elle est basée sur la technologie des séries temporelles et spatiotemporelles. Warp 10 a été conçue pour traiter les données de capteurs et, plus globalement, de tout type de mesures.
De plus en plus utilisée, notamment par les grands acteurs du numérique, la technologie des séries temporelles et spatiotemporelles va révolutionner le champ de l’analyse de données (Cf. Article). Pourquoi ? Parce que les données proviennent de sources sans cesse plus nombreuses et qu’elles se traitent sur des temps de plus en plus courts. Les données sont dynamiques et le mouvement s’accélère alors même que les systèmes d’information sont avant tout conçus pour des temps longs.
La technologie n’est souvent pas, en soi, le critère prioritaire pouvant guider l’organisation et la gestion des données. Pourtant, la sous-estimation de l’impact des évolutions technologiques aboutit trop souvent à une impasse au moment du passage à l’échelle. Il ne reste alors plus qu’une seule option : s’en remettre à un grand acteur du numérique tout en légitimant une telle décision par le constat sans appel qu’il n'y avait pas le choix.
Le monde de la santé n’échappe ni à ce risque, ni à l’issue de cette trajectoire.
Une construction sur 30 ans
Sans revenir sur la définition des données de santé telle qu’affirmée dans le Règlement Général sur la Protection des Données (RGPD), on notera les trois grandes catégories proposées par la CNIL :
- Les informations relatives à une personne physique
- Les informations obtenues lors de tests et d’examens
- Et enfin celles concernant une pathologie, issues du personnel médical ou d’un dispositif technique.
Un rappel historique sur les données de santé dans les débats publics est ici proposé en partant de la loi de 1991 qui consacre la naissance du Dossier Médical Informatisé. Il permet de mettre en évidence les quatre objectifs visés par la constitution de bases de données de santé :
- Optimiser la gestion des moyens humains et des moyens techniques. Les données sont celles des différents systèmes d’information des établissements de santé (PMSI) et de tout ce qui fait le lien avec les professionnels de santé.
- Assurer la gestion des assurés sociaux et garantir le meilleur traitement des échanges financiers entre tous les acteurs de la chaîne. C’est notamment la fonction de la CNAMTS (Caisse Nationale d’Assurance Maladie des Travailleurs Salariés).
- Assurer, au travers du Dossier Médical Partagé (DMP), un suivi médical des patients et de tous les actes le concernant, pour prendre les meilleures décisions et améliorer leur santé.
- Offrir aux acteurs de la santé publique et de la recherche des canaux d’accès à des données anonymisées ou pseudonymisées collectées auprès de sources différentes pour concourir directement à l’amélioration de la santé publique. C’est l’objet du Health Data Hub. Il s’appuie sur les données du Système National des Données de Santé (SNDS) et principalement sur le Système National d’Information Interrégimes de l’Assurance Maladie (SNIIRAM).
Une organisation avec des nombreuses sources de données
Un empilement de strates et une conjonction de silos : tel est ce qui résume la vision que l’on peut avoir des données de santé avec des organisations nombreuses, des métiers très variés, une dualité de pouvoirs médicaux et administratifs, ou encore des modes de financement publics et privés. Cette complexité est encore renforcée par des applications qui portent le poids de leur histoire. Les initiatives en matière d’analyse des données se heurtent très vite à la réalité de la diversité de l’écosystème de la santé et de l’éclatement des responsabilités.
Partant d’un mode de représentation utilisé par le ministère de la Santé sur la doctrine du numérique associé à la feuille de route de MaSanté2022, le cadre global des données de santé peut être synthétisé de manière présentée ci-dessous.
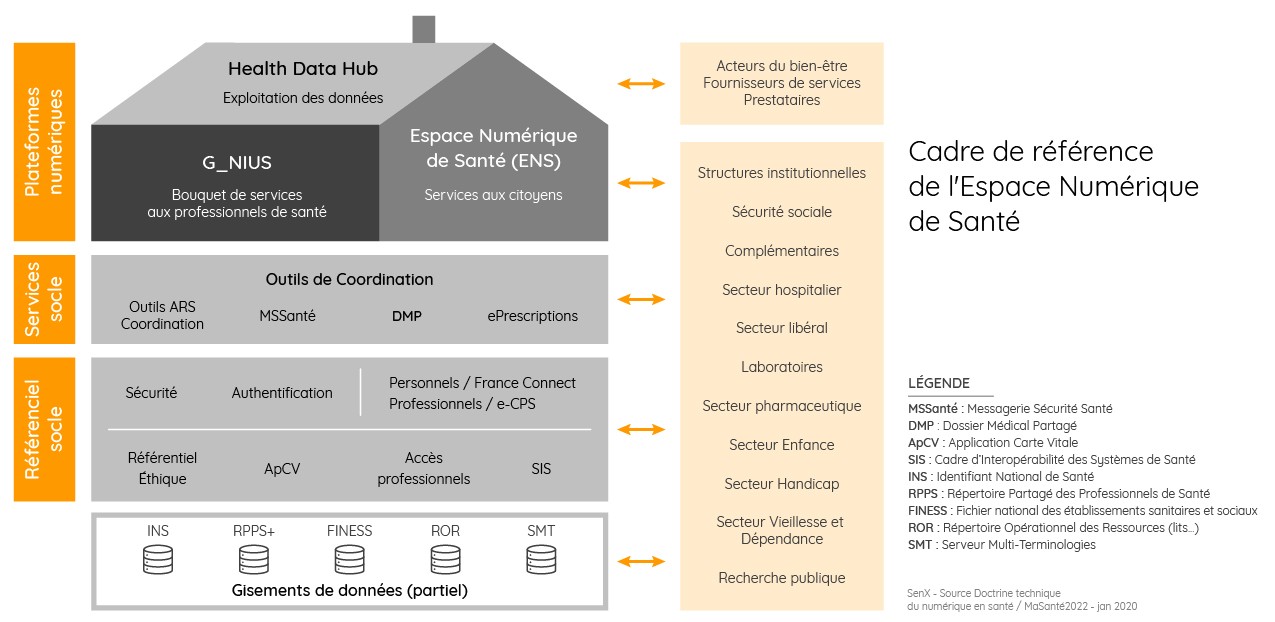
Cette représentation n’est évidemment pas exhaustive, loin de là.
Pour ce faire, il conviendrait de pouvoir faire apparaître les nombreuses autres sources de données telles que celles issues de :
- l’ATIH (Agence Technique de l’Information sur l’Hospitalisation),
- la FEDORU (Fédération des Observatoires Régionaux des Urgences) intégrant aussi les donnes des SAMUs et SMURs,
- des caisses de retraite (dont la CNAV),
- de l’Inserm comme le CépiDc sur les causes de décès ou encore l’ORPHA sur les maladies rares,
- de l’AFAQAP (Association Française d’Assurance Qualité en Anatomie et Cytologie Pathologiques). Elle donne accès à une série de bases sur différents types de cancers,
- d’Epidemiologie-France qui recense 500 sources (bases médico-économiques, cohortes, registres),
- ou encore de l’observatoire NutriNet-Santé sur les habitudes en matière de nutrition.
Compte tenu de la variété des sources de données, il apparaît assez naturel de faire un lien entre l’exploitation qui peut en être faite et l’amélioration globale d’un écosystème au profit de la santé publique en France. Permettre l’accès aux données de toute la chaîne en assurant les contrôles indispensables pour garantir protection des données : c’est tout l’objet du Système National des Données de Santé (SNDS).
Données de santé : sortir de l’impasse Share on XLe SNDS recense quatre types de travaux mis à disposition depuis 2006 :
- les « études d’ordre administratif ou technique (…) faisant référence à l’optimisation du processus de traitement de données, des procédures techniques, des algorithmes de détection de pathologies ou d’état de santé » ;
- les études sur les « parcours de soins » des patients et sur « l’offre de soins » ;
- celles portant sur la consommation de soins ou les différents types de prestation et leurs coûts ;
- et enfin, les études épidémiologiques et de pharmacovigilance.
Les méthodes classiques limitent l’analyse de données
Outre la question de la gouvernance et de la protection des données de santé, leur analyse se heurte à une difficulté majeure : l’interopérabilité. À chacun des environnements techniques correspond autant de systèmes, plus ou moins complexes. Ils disposent tous de leurs terminologies, leurs formats et leur interprétation de la donnée.
Le modèle classique d’analyse de données consiste à extraire des données (ETL/Extract Load Transform) de base, souvent différentes, et à constituer un entrepôt de données (Data Warehouse) sur la base d’un référentiel commun en matière de format et de sémantique. À partir du quoi, des analyses (Analyse Décisionnelle/Business Intelligence ou tout simplement BI) pourront être effectuées.
Ce processus s’applique parfaitement à des bases de données relationnelles, répandues dans toutes les entreprises et autres organisations.

Tout comme l’expression Data Sciences est désormais souvent préférée à celle de « Business Intelligence », la terminologie Data Warehouse a laissé place à celle du Data Lake, laquelle est associée à celle du Big Data. Mais les mots peuvent vite sonner creux dès lors que le message dont ils sont porteurs ont avant tout une valeur marketing. C'est généralement le cas avec le recours avec ces mécanismes d’extraction qui sont lourds et qui ne peuvent souvent être activés que la nuit pour ne pas dégrader les performances des applications principales. Ils nécessitent par ailleurs de s’appuyer sur un référentiel commun d’interopérabilité.
Les limites de la standardisation
De nombreux travaux sont menés pour constituer un tel référentiel dans l’univers de la santé, comme c'est aussi le cas dans tous d’autres secteurs. Plusieurs initiatives de standardisation des données existent à l’échelle internationale. Avec les travaux menés par l’Agence Numérique en Santé (ANS) sur le « Cadre d’Interopérabilité des Systèmes d’Information de Santé (CI-SIS) », la France se montre très active comme en témoigne le dernier point fait à ce sujet en novembre dernier.
Cependant, dans la santé comme dans beaucoup d’autres secteurs, leur mise en œuvre opérationnelle reste très laborieuse. On peut dénombrer au moins cinq raisons :
- les systèmes d’information portent le poids de leur histoire et n’ont pas été conçus en tenant compte du besoin d’interopérabilité ;
- la normalisation est un domaine complexe. Pour en juger, il suffit de parcourir les documents publiés par l’ANS. Elle nécessite un investissement important et des experts spécialisés qui ne sont plus en prise directe avec les besoins métiers ;
- la normalisation qui nécessite des temps longs est rarement compatible avec l’innovation qui est tirée par la technologie et concurrence sur marché où la vitesse joue un rôle incontournable ;
- il n’existe généralement pas une normalisation unique, mais de nombreuses initiatives qui sont autant de chapelles, lesquelles représentent des intérêts non nécessairement convergents. Les groupes privés rejoignent ainsi plusieurs instances de standardisation et participent à des initiatives, forums, alliances qui sont intéressantes sur le fond, mais qui participent à la complexité d’ensemble. À cela se rajoute le jeu des pays où ensembles géopolitiques qui chacun cherchent à exister sans avoir le même poids ;
- les acteurs du marché n’ont pas nécessairement intérêt à favoriser la normalisation. Sauf lorsqu’ils peuvent tenir une position de leadership sur l’une d’entre elles.
Les standards sectoriels restent cependant un objectif incontournable et il faut encourager leur utilisation lorsqu’ils existent. Il faudrait ici un autre développement sur, par exemple, les résultats et les limites des travaux de la HL7 Foundation, d'OpenEHR ou encore de l’OHDSI (Observational Health Data Sciences and Informatics).
Il est assez facile de se réfugier dans l’incantation ou, à l’instar de ce que propose la Cour des Comptes, vouloir traiter le sujet en rendant « opposables aux éditeurs de logiciels les référentiels d’interopérabilité »[1]. Pourquoi pas aussi "imposer l’interopérabilité" comme le propose en juillet 2020 le rapport dévaluation sur le dossier médical partagé et sur les données de santé ? On peut toujours pointer du doigt les lacunes des pouvoirs publics dans ce domaine. Ils font plus simplement face à une réalité complexe et extrêmement mouvante.
En attendant, il faut agir avec des choix qui sont faits le plus souvent au cas par cas. Les data scientists sont recrutés en nombre. Encore faudrait-il que leur savoir et expertise soient utilisés au mieux à savoir la modélisation et l’analyse de données. Cependant, ils vont passer une partie significative et le cas échéant dominante de leur temps sur la qualification, l’extraction, le nettoyage et la mise en forme des données.
De nombreuses sociétés se sont spécialisées dans cette activité de data sciences sur mesure. Le data scientist saura ainsi, cas d’usage par cas d’usage sur un sujet de santé, établir des corrélations liées à l’usage de certains médicaments, détecter des anomalies dans les parcours de soins, prévoir l’occupation des lits, sortir des tableaux de bord croisés … Mais rationaliser et automatiser de tels traitements est un tout autre défi qui peut, selon le cas, s’avérer impossible. De même est-il difficile de capitaliser les travaux d’analyse jusqu’à devenir inexploitables lorsque le data scientist s’en va vers d’autres horizons. Dans le meilleur des cas, le travail réalisé est documenté. Au pire, tout disparait : la savoir, l’expertise, la capacité à exploiter des résultats …
La complexité inhérente aux données du SNDS
L’un des objectifs du Health Data Hub est précisément de fournir un environnement propice aux travaux d’analyse. Au-delà de l’agrégation des données, il s’agit de mettre des outils fonctionnels et sécurisés.
Cette construction engagée par le SNDS, se fait à partir de bases de données de type relationnel qui organisent les données en fonction de leur contenu métier. Elles s’appuient sur des tables et des relations entre elles qui répondent à des exigences fonctionnelles. L’agrégation des données issues de ces différents environnements revient à créer un nouvel étage qui vient se superposer aux bases d’origine.
On obtient une architecture dont la complexité n’est que le reflet fidèle de chacun des sous ensembles. Or par construction, les bases relationnelles se caractérisent par des imbrications si fortes que les évolutions se font toujours à la marge. On remet rarement en question ce qui existe et qui fonctionne. Modifier, c’est d’abord ajouter des composants, de nouvelles relations et de nouvelles données.
La conséquence est qu’un système d’information classique porte toute son histoire. Que dire alors d’un ensemble qui entend les fédérer ?
Le SNDS a été construit ainsi. Depuis quelques années, des réflexions ont été engagées pour le faire évoluer en s’appuyant sur des technologies plus récentes.
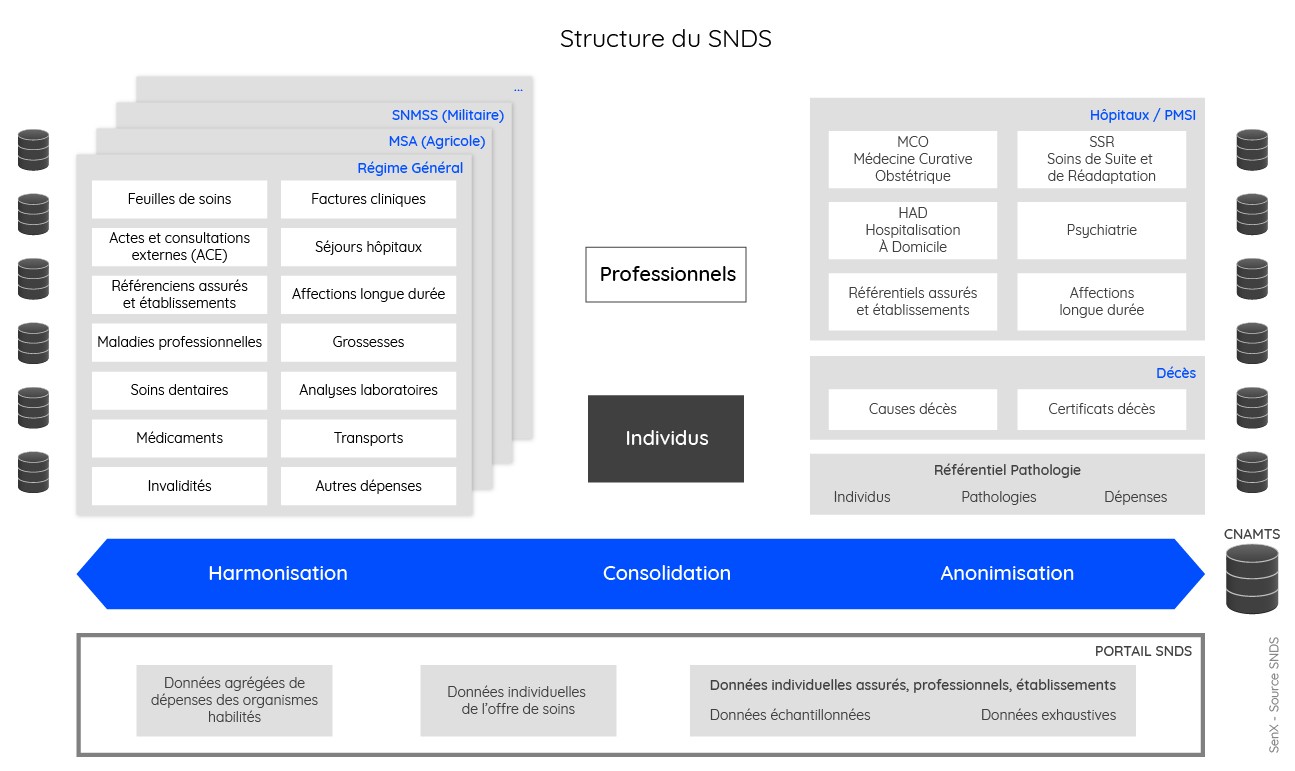
Cependant, l’exploitation d’une telle structure de données nécessite une expertise que peu d’acteurs possèdent en France.
Les séries spatiotemporelles et l’importance des données brutes
SenX propose une technologie – Warp 10 – qui s’applique à l’origine aux données de capteurs.
Si le champ d’application naturel n’est pas celui des données issues des applications métiers, dans le domaine de la santé comme pour d’autres secteurs, la technologie de Warp 10 facilite considérablement les travaux d’analyse de données tout en garantissant en outre des performances très élevées, une sécurité et une neutralité technique, une évolutivité et une garantie sur le caractère pérenne de l’architecture technique.
Dans les données de type séries temporelles, chaque enregistrement est considéré comme une donnée brute liée à une mesure. Celle-ci est associée à son heure d’émission (horodatage). Dans le cas de Warp 10, la géolocalisation – quand cette donnée existe – y est aussi associée. Contrairement à une organisation en tables, les données sont stockées sans chercher à leur donner du sens. Toutes les données s’apparentent à des mesures. Les données structurantes lors du stockage sont simplement l’horodatage et la localisation.
Fini le schéma avec des mécanismes d’extractions et de constitution d’une base intermédiaire. Tous les événements et mesures sont stockés dans une base séries temporelles (TSDB) ou spatiotemporelles. Celle-ci alimente alors indifféremment des applications métiers comme des modules d’analyse pour des tableaux de bords, des analyses complexes jusqu’à tirer bénéfice de tout ce que peuvent apporter des outils de Machine Learning.

En outre, la question de l’interopérabilité se trouve simplifiée.
Une autre vision des réservoirs de données
Comme évoqué précédemment, une méthode classique suppose d’extraire les données et de convertir les formats en lien avec une sémantique spécifique. Dans le cas des séries temporelles, tout est ramené à des historiques de mesures d’événements stockées en tant que données brutes. C’est sur ces données brutes que l’analyse s’applique. La question du format et du sens viendra seulement à la sortie. Ce dispositif nécessite naturellement de disposer de données horodatées et c’est le cas de nombre de données de santé.
Beaucoup de données peuvent en effet être qualifiées dans le temps et géolocalisées. La plupart des données représentées dans le schéma ci-dessous (excepté les données issues de la recherche en génomique) ont une composante temps. Elles sont aussi généralement associées à une géolocalisation.
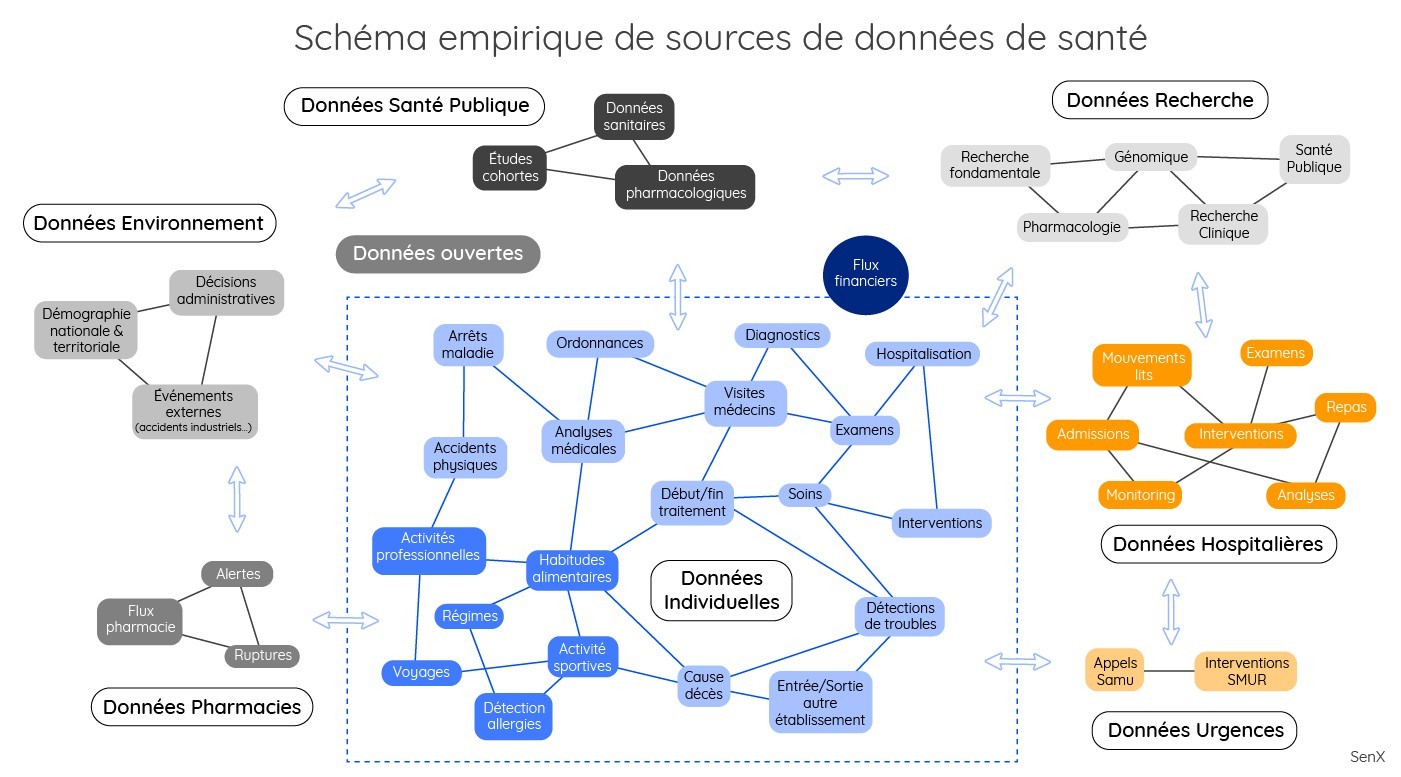
Aujourd’hui, chaque application, qui vise à tirer profit de l’analyse de données croisées, nécessite un travail préalable très important. Il faut chercher dans les bases, effectuer des requêtes spécifiques au cas par cas, en tenant compte de chaque format, nettoyer les données en fonction des spécificités métiers de chaque source… À l’inverse, une approche basée sur les séries spatiotemporelles permet de constituer des réservoirs de données de manière plus simple avec une organisation des données simplement basée sur le temps et le cas échéant la géolocalisation.
Le recours à ce type de technologies permet d’aborder l’analyse des données sous un angle différent. Il ouvre la voie à l’exploration d’historiques de sources de données très variées sur tout type d’événements qui concernent la vie du patient.
Une expérience non aboutie avec le Health Data Hub
Dès 2015, nous avons proposé d’analyser les données relatives aux prescriptions accessibles sur le SNIIRAM. Une ordonnance peut en effet être considérée comme un capteur auquel sont associées des informations séquencées dans le temps et géolocalisées. Dès lors, la conversion des données en séries spatiotemporelles est possible.
L’intérêt d’une solution telle que Warp 10 est alors évident. Elle dispose d’une librairie de plus de 1000 fonctions qui permet d’explorer des historiques profonds de données : de statistiques usuelles à la détection de patterns, la détection de corrélations, la détection d’anomalies… Par ailleurs, Warp 10 facilite grandement les approches basées sur l’intelligence artificielle. Celles-ci s’appuient sur des mécanismes d’apprentissage appliqués à des historiques de données.
Le projet codata
Nous avons pu finalement établir un lien avec le Health Data Hub dans le cadre de l’initiative Codata. Initiée au printemps 2020 en lien avec l’épidémie Covid-19, Codata a permis d’engager une série d’échanges entre les acteurs français du traitement de données. Un certain nombre de sujets sont ressortis. Parmi eux, l’analyse de l’historique pharmacologique de la population avec en toile de fond, la controverse autour de la chloroquine.
Nous avons été confrontés aux conditions d’accès très restrictives aux données avec une première difficulté de taille. En effet, nous avions l’obligation de soumettre un sujet de recherche scientifique aux objectifs détaillés. Le sujet était là : "l’identification de molécules inhibitrices de la Covid-19". Le sujet étant porté par Etienne Decroly (Directeur de recherche au laboratoire Architecture et fonctions des macromolécules biologiques du CNRS/Aix-Marseille Université, membre de la Société française de virologie du CNRS) en lien avec Pierre Sonigo, directeur R&D chez Sebia et auparavant directeur de recherche à l’INSERM.
Nous souhaitions mener le projet en deux phases. La première devait qualifier la faisabilité technique de la migration des données du SNDS/SNIIRAM vers la technologie de séries spatiotemporelles de Warp 10. La seconde était destinée à mener le travail scientifique sous la conduite du CNRS.
Un tel phasage se heurte au principe de finalité du traitement qui impose de décrire l’ensemble du processus et donc de détailler les objectifs des travaux de recherche. Il faut pouvoir justifier la demande d’accès à telle ou telle autre donnée. C'était là un obstacle difficile à franchir pour nous qui ne pouvions prendre le risque de monter un projet avec les CNRS sans même garantir que nous pourrions le réaliser. Sur le principe, nous regrettons les contraintes imposées par le principe de finalité qui ne permet pas de mener des travaux sur un objectif technique avant de pouvoir engager des moyens un projet de recherche à finalité médicale. Rappelons que l’un des intérêts majeurs de l’analyse des données consiste à trouver des signaux faibles alors que ceux-ci ne pouvaient être même imaginés. Il y a une contradiction de fond sur ce point intangible de la doctrine de la CNIL.
Projet prometteur mais au point mort
Nous sommes finalement parvenus à conduire une expérimentation sur des données de test. Le résultat s’est avéré concluant. Nous avons pu convertir les données fournies en séries temporelles ou spatiotemporelles quand la géolocalisation faisait sens. Il n’a pas cependant été possible d’aller au-delà de cette première étape. En effet, cela impliquait l’utilisation de Warp 10 sur l’architecture cloud du Health Data Hub. Compte tenu des controverses liées au choix de Microsoft et de la charge de travail de nos interlocuteurs, nous avons dû renoncer à ce projet.
Fort du test réalisé, nous pouvons assurer que Warp 10 permettrait d’analyser les données du SNDS/SNIIRAM avec une approche totalement nouvelle qui faciliterait grandement leur analyse. Dès lors que la conversion des données du Health Data Hub en séries (spatio) temporelles est disponible, il pourrait être répondu aisément d’un point de vue technique aux objectifs assignés par le rapport Villani, à savoir la possibilité de mener des études : "1- De populations traitées en vie réelle, 2- sur l’usage de dispositifs médicaux, 3- de pharmacovigilance, 4- d’essais thérapeutiques « virtuels » évitant les coûts élevés d’études cliniques, 5- en vue de la détection de « signaux faibles » dans la population générale, d’identifier les populations éligibles à des essais thérapeutiques ou interventionnels ».
Nous restons de ce point de vue demandeurs de poursuivre les premiers travaux engagés.
Analyse des données et santé et santé publique
Les controverses sont nombreuses sur l’utilisation des données de santé à des fins d’analyse. Pourtant, les risques de porter atteinte aux données personnelles des patients avec les données stockées dans le Health Data Hub sont quasi nuls.
Ils sont sans commune mesure avec les risques de piratage encourus par les systèmes d’information des organismes et structures de santé, publiques comme privées. La CNIL a mis en demeure en 2018 la Caisse nationale de l’assurance maladie des travailleurs salariés (CNAMTS) de renforcer la sécurité du SNIIRAM dont elle assure la gestion technique, en tant que responsable de traitement. La presse et les sites d’information se font régulièrement fait l’écho des attaques dans ce domaine des données de santé. On peut noter la récente attaque au Québec de la société Medisys et toutes les attaques liées aujourd’hui aux recherches sur les vaccins contre des sociétés parmi les mieux protégées. Nombre de données sont en clair dans les systèmes d’information et elles ne sont pas anonymisées.
Le choix de Microsoft pour l’hébergement des données du Health Data Hub, a alimenté cette controverse. Ce choix impose notamment de recourir aux différents outils mis en place par l’éditeur américain, pour traiter les données. Au-delà de ce type de contraintes que nous percevons comme contestables, ce choix donne des arguments à tous ceux qui remettent en cause la raison d’être du Health Data Hub. Il déplace malencontreusement le centre de gravité du débat qui devrait être : explorer l’éventail des technologies disponibles tendant à améliorer la santé publique tout en se prémunissant des risques dont les technologies de traitement de données peuvent être porteuses.
On ne peut ne satisfaire du système tel qu’il existe aujourd'hui. La conjonction des contraintes imposées à la fois par le RGPD et les conditions définies par la CNIL, puis surtout par le cadre technique d’accès aux données tel qu’il est prévu, et enfin par la courbe d’apprentissage de l’organisation des données avec ses silos, est de nature à décourager les plus les plus désireux d’apporter leur contribution à l’amélioration de la santé publique.
Le lien entre données et santé, un sujet largement traité depuis plusieurs années
L’un des meilleurs spécialistes de ce domaine est probablement Éric Topol, qui a énormément travaillé sur l’apport du numérique dans la santé. Il a notamment réalisé une sorte de feuille de route pour le NHS en Grande-Bretagne sur l’apport du numérique dans la santé. Éric Topol y accorde une place particulière au sujet des données.
Il faut également lire l’article de Mathieu Corteel (Chercheur, spécialiste en histoire épistémologique de la médecine et en épistémologie du calcul de probabilités) : « Le hasard clinique ou la crise de la rationalité médicale ». Il s’agit d’une forme d’introduction au livre « Le hasard et la pathologie », publié récemment. Très critique sur les excès de l’Intelligence Artificielle, telle qu’imaginée par Cédric Villani, Mathieu Corteel explore cette quête contrariée entre la personnalisation des soins et la place de technologie dans l’assistance, voire la prise de décision en matière de santé.
L’autre volet des données de santé : les appareils et dispositifs médicaux
La plupart des données évoquées précédemment peuvent être qualifiées de médico-administratives (typiquement une prescription médicale). On peut aussi ajouter que parmi les autres données qui sont purement de santé, beaucoup d’entre elles sont, dans les applications qui les traitent, liées à des processus de même nature.
L’émergence des objets connectés a fait émerger un nouveau type de données. Ce n’est pourtant que la partie visible et grand public des données issues des dispositifs techniques allant des équipements de bien être personnels aux dispositifs médicaux. Souvent évoqué mais finalement peu traité, ce sujet va occuper progressivement une place considérable dans la thématique globale des données de santé.
Ce sera l’objet de deux nouveaux articles qui seront publiés prochainement.
| Vous souhaitez discuter de vos problématiques liées aux données de santé (ou de tout autre domaine) ? SenX peut vous aider. Contactez-nous. |
[1] Rapport « Les services publics numériques en santé : des avancées à amplifier, une cohérence à organiser ». Ce rapport fait le constat suivant : « L’interopérabilité entre services numériques en santé est indispensable pour que ceux-ci puissent servir d’appui aux parcours de soins (…). Élaborer, en concertation avec l’ensemble des acteurs concernés, un calendrier d’opposabilité à la fois ambitieux et respectueux des contraintes des industriels apparait comme une responsabilité que les pouvoirs publics ne sauraient plus longtemps éluder ».
Read more
Our vision of Industry 4.0 and the 4 stages of maturity
How can you tell which Time Series Database is suited to your needs?
Les données des dispositifs médicaux
Co-Founder & former CEO of SenX