Warp 10 3.0 introduces changes into the available versions. Discover which flavor is the most suitable for your project.

Warp 10 3.0 comes in three flavors: standalone and standalone+, with or without high availability, and distributed. As Warp 10 3.0 switched from HBase to FoundationDB, this leads to new combinations.
This article will help you to choose your Warp 10 3.0 flavor.
Taking the time to make the right choice
When possible, take time to do a proof of concept: here are the criteria you will have to focus on, and the human time needed to prepare them:
- Number of GTS: this is the easiest one. Start with a simple model (one GTS per measure per asset), and extrapolate.
- Number of datapoints and disk space: You need to build a realistic data simulator. This will take you a few days, you will need to discuss this with the data producers or use existing datasets to build something realistic. Never do these tests with random data (this is the worst-case entropy).
- Requests and operations per second: You also need a realistic simulator. This will take you a few weeks, to understand what the end users really want, and to learn how to do the corresponding requests in WarpScript.
| Help, the project is already late, I do not have three weeks to do preliminary work! (Project leader) |
| → Contact SenX. We will help you, that's the purpose of the proof of concept service we sell. You buy the security to start the right way. |
| I am a student, I have no time and no budget! (The intern who should move the company away from csv files for time series) |
| → At least, ask for a good server: 8 cores, 32GB of RAM, 1TB of SSD, gigabyte network access. Then install Warp 10 3.0 standalone with LevelDB backend. If your administrator imposes you a virtual machine, ask for the maximum IOPS. It will be simpler to decrease requirements in the future than to increase them. Then ask for help on the Warp 10 Lounge. |
Once you have realistic datasets and user requirements, follow the guidelines below.
Understand the minimum requirements
| Warp 10 standalone with LevelDB | – Java (8 to 20) – can run on small embedded targets |
| FoundationDB | – 8GB RAM per process – SSD storage with >5% disk free. – from 1 to xxx instances. |
| High availability | – a load balancer (nginx, haproxy) |
| Warp 10 distributed | – Java (8 to 20) – Zookeeper – Kafka – FoundationDB – High-speed private network between servers |
Requests and ops
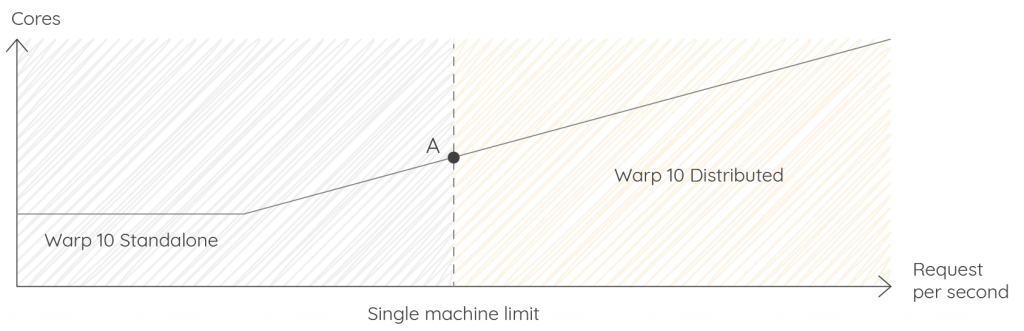
This one is the simplest to measure as soon as you build your request and data simulator. Point A represents the limit of vertical scaling (128 threads at the time of this writing).
- By default, Warp 10 limits ingress and egress threads.
- By default, Warp 10 is configured to work with 1GB of RAM.
- When doing tests, raise Warp 10 limits, and look at CPU and network loads. Depending on your provider, the network can be a bottleneck.
There are two ways to go beyond point A:
- You do not store and fetch a lot of datapoints, but your simultaneous requests are CPU intensive (Fourier or wavelet transforms, tons of BUCKETIZE/MAP…): you can use datalog (replicate all data):
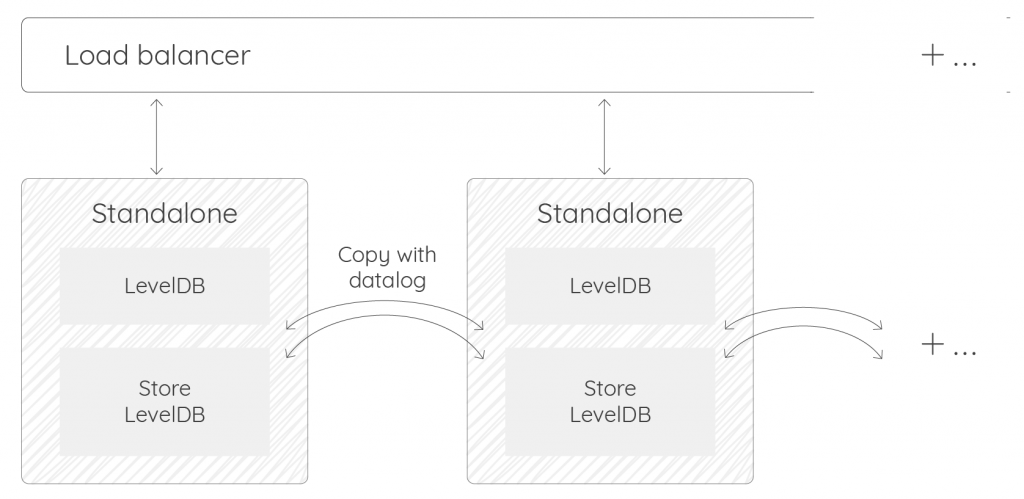
- You store or fetch lots of datapoints and your requests are CPU intensive: deploy Warp 10 distributed, with a load balancer in front of multiple egress machines. That is the most future-proof and flexible option. It cannot be done with LevelDB, but it can be done with a few FoundationDB nodes:

There is a third way, but much more complex (use datalog for directory only and share the same FoundationDB backend).
Number of datapoints
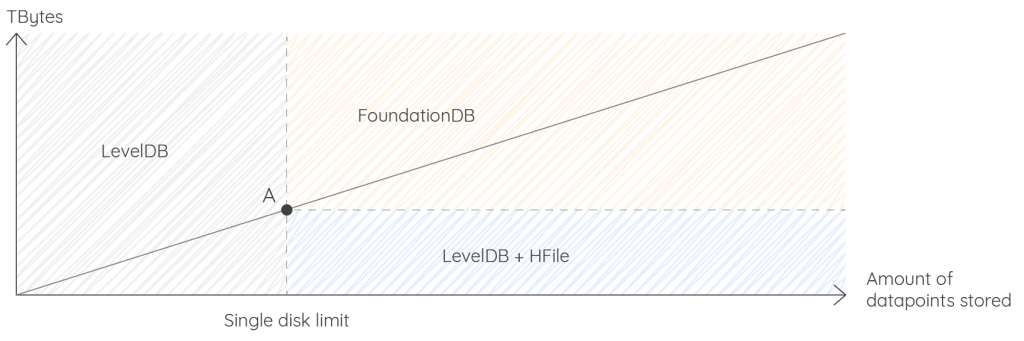
As compression enters the game, you need to extrapolate from existing datasets or realistic simulated data.
If you know you can reach point A in the next years, you need to ask yourself the following questions:
- Can my data be cold?
- What is my data lifecycle?
You may need to erase data after a few years because of regulations or contractual requirements. Since Warp 10 3.0, there are functions to reclaim disk space of a LevelDB backend when you delete the oldest data, without waiting for compaction.
Cold data means immutable data. In some use cases, data is cold as soon as it is produced (it means you won't change data). The hot data time window is defined by the maximum time you need to consolidate data. If you manage a fleet of devices, the window is defined by the delay you allow each device to push their data. It can be a few minutes or over a year.
If your data is cold before reaching point A, the most cost-effective solution is to use HFile. Instead of having several servers, you just need object storage. HFile is not part of the Warp 10 3.0 open-source platform, but the economy is worth the license cost. In this case, the setup is:
- a single server with Warp 10 standalone + LevelDB
- dump the oldest data to HFile every week or month, and erase them from the Warp 10 instance.
Moreover:
- The reading speed of HFile, in datapoints per second, is better than any other backend.
- The compression of datapoints in HFile is better than any other backend.
- The data in Hfile format can easily be manipulated interactively as if the data were in a Warp 10 instance or in batch using Spark.
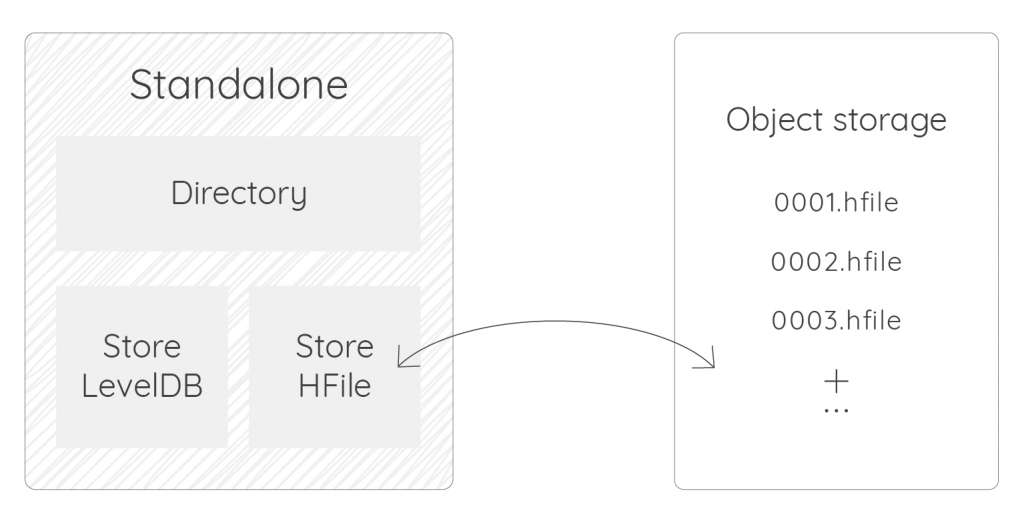
If you know you will reach point A sooner or later, instead of using the LevelDB backend, you can start with FoundationDB from the very beginning. This is what we call the Standalone+ version, only available since Warp 10 3.0. To install Standalone+, read the instructions here.
In this case, the setup is:
- A single server with Warp 10 standalone + FoundationDB (one or more process)
- Add FoundationDB servers when you reach limits.
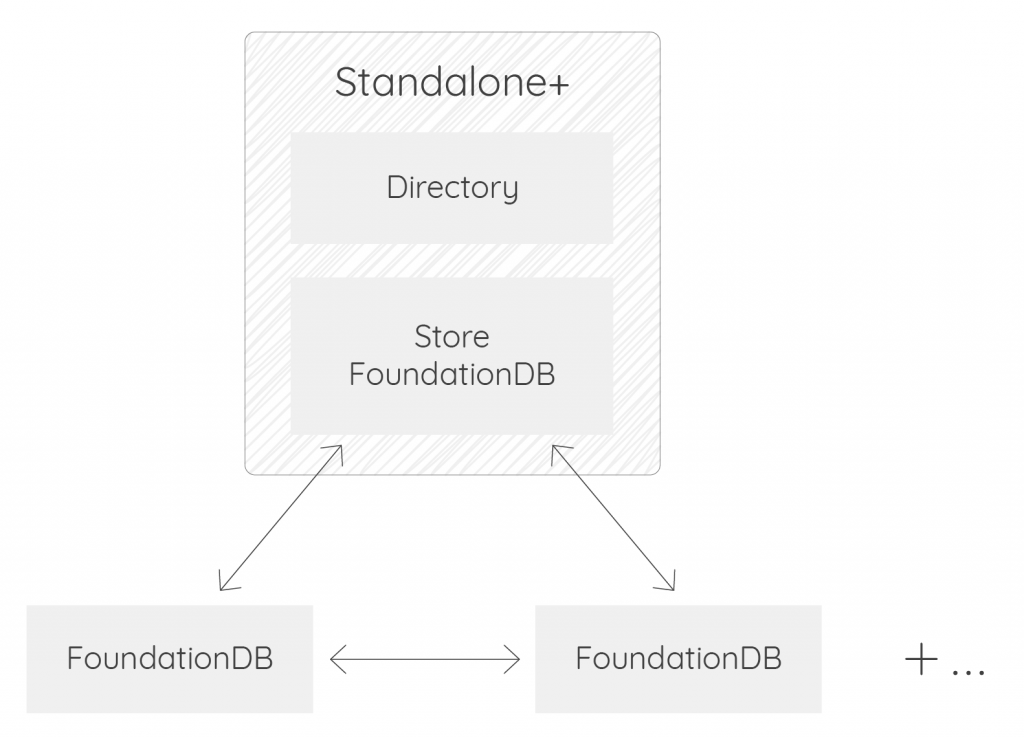
And when a single server can no longer cope with your requests and ops load, that standalone-like deployment can be morphed into a distributed one by simply adding Kafka and replacing the single server with multiple servers handling the various Warp 10 roles, all without having to migrate data since they are already in FoundationDB.
Remember FoundationDB requirements, you cannot play with weak 2 vcores 8GB virtual machines if you go this way.
Number of GTS
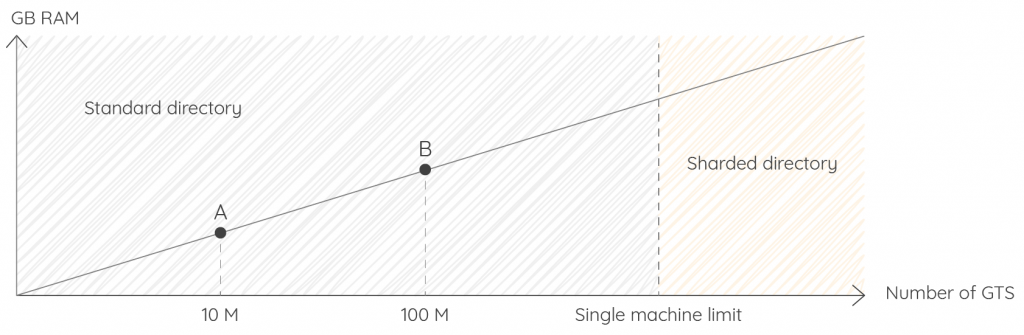
The directory component is the index of all the GTS known in the database. It is loaded in RAM during Warp 10 startup. The size depends on the size and number of labels and classnames, but the RAM usage is linear. A single Warp 10 instance can manage millions of GTS easily.
During the first tests, if you reach point A quickly, then you must question your data model. The data model is very important to limit cardinality. Again, SenX experts are here to help you choose the best modeling.
If you think you will reach point B sooner or later, also ask yourself about the data lifecycle. Erasing all the datapoints does not remove the entry in the directory. It could be great to activate last activity tracking to purge directory on a regular basis.
If you think you will reach the machine limit, then you have to switch to Warp 10 distributed, and have several directory nodes, with a sharding. Maybe 16 shards to be sure.
For information, the all-time record of GTS number in a Warp 10 distributed version is more than a billion (8 shards, ~150 million gts per shard).
Sharding and activity tracking are part of Warp 10 3.0, but are deactivated by default.
| What if I choose the wrong Warp 10 3.0 flavor for the project start? (Anxious project leader) |
| → Choosing Warp 10 3.0 was the most secure choice. A wrong initial setup is not a big deal. Your WarpScript will remain the same, and data can be moved. |
Conclusion
Warp 10 does scale, more than ever with 3.0 and FoundationDB backend.
Warp 10 3.0 new flavors bring a lot of flexibility. As every use case is different, «future-proof» has not the same meaning for everyone…
These guidelines are not universal, SenX experts are here to help you to make the right choices, just contact us.
Read more
November 2024: Warp 10 release 3.4.0
How to migrate to Warp 10 3.0?
Deploying a Warp 10 Standalone+ instance

Electronics engineer, fond of computer science, embedded solution developer.