In this tutorial, we will see how to aggregate by calendar duration that can be irregular (like months or years for example)

One particular feature of WarpScript is that it allows you to make usual operations on time series in a few lines of code with powerful frameworks.
In this tutorial, we will see how to aggregate by calendar durations that can be irregular (like months or years, for example).
Learn more about WarpScript if you're not familiarized with it yet.
First, we will remind how the BUCKETIZE framework works. Then we will see how to bucketize with monthly buckets and how to operate on bucketized series. Finally, how to bucketize with buckets of any calendar duration.
Reminder on BUCKETIZE
If you need to resample your data, align ticks of multiple time series and aggregate along buckets of time, you can use the BUCKETIZE framework.
BUCKETIZE splits the time axis in buckets of times of same width. Values that fall in each bucket are aggregated and are associated to the end timestamp of each bucket.
For example, consider a constant time series, valued at 1 everywhere, and having ticks ranging from 2 to 10 included. BUCKETIZE applied with the bucketizer.sum, using a bucketspan equal to 5 will create two buckets:
- One bucket at tick 10 with the value 5
- One bucket at tick 5 with the value 4
You can check this on this example:
NEWGTS
2 10 <% NaN NaN NaN 1 ADDVALUE %> FOR
[ SWAP bucketizer.sum 0 5 0 ] BUCKETIZEWhen a time series is bucketized, further operations can make the simplifying assumption that the ticks are well-structured by being evenly separated. So, bucketizing time series as a preprocessing step is often advantageous.
Possible limitation of BUCKETIZE
However, say I have some data that I want to aggregate monthly. Then I cannot use BUCKETIZE since it can only work with buckets of constant bucketspan, whereas months can span either 31, 30, 29 or 28 days.
So, I'd have to use something else, like a MAP with a pre-window parameter large enough after which I filter the data points on each computation of the sliding window, or by traversing manually the values of my time series using loops.
These methods are not optimized, and worse, the result is not bucketized so functions working only on bucketized GTS cannot be applied afterward.
Hopefully, there is still a way to use the BUCKETIZE framework and overcome this limitation! With revision 2.5.0, there is a set of functions and macros that speeds it up. Read on.
At the time of writing this article, Warp 10 v2.5.0 is coming soon: preview is available on the sandbox, on the endpoint https://sandbox.senx.io/api/v0/exec). You can compile Warp 10 master if you need these function now on your instance.
BUCKETIZE by month
For example, to bucketize with buckets spanning calendar months, you can use the macro @senx/cal/BUCKETIZE.bymonth (this macro is available from SenX's WarpFleet repository which is enabled per default in the WarpFleet resolver):
http://studio.senx.io/#/editor/snapshot/00059f9126ed64de-0-7-59a63fc949fc1653
// load a dataset of hourly temperature in 27 us cities
// and convert Kelvins to Celsius degrees
@senx/dataset/temperature <% DROP 273.15 - %> LMAP
// bucketize monthly
[ SWAP bucketizer.mean ] @senx/cal/BUCKETIZE.bymonth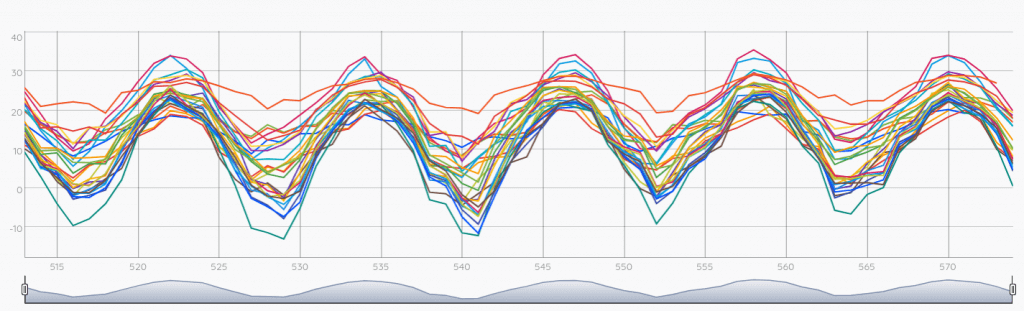
So the macro did it, the result is bucketized. Each tick represents the value of the mean temperature in a month!
Question: … but wait, why the time axis has indices instead of actual timestamps ?
Answer: This is just a convention so that the resulting GTS are considered bucketized. For instance, month 520 is the 521st month since Unix epoch (the month that starts with Unix epoch is the 0th). To restore the normal time axis, you can use the function UNBUCKETIZE.CALENDAR.
https://snapshot.senx.io/00059f913c38ac91-0-5-2b94f1b858e385ca
// previous code
[ @senx/dataset/temperature <% DROP 273.15 - %> LMAP bucketizer.mean ] @senx/cal/BUCKETIZE.bymonth
// unbucketize
UNBUCKETIZE.CALENDAR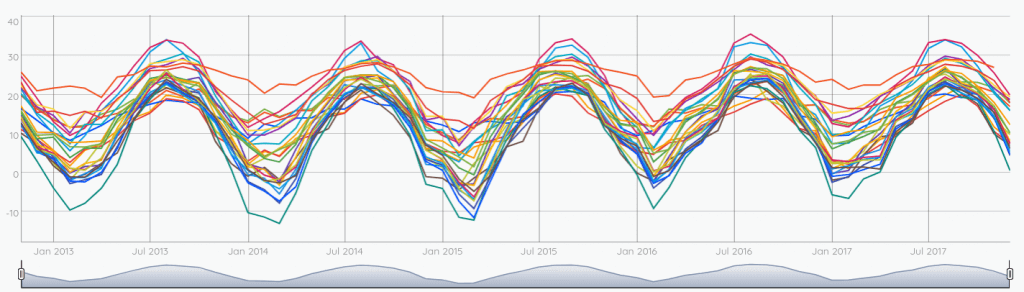
This time, the time axis is back to normal. There is a tick at the end boundary of each month, and the value is the mean of temperatures during this month.
Question: So then, why not fuse both macros into a single one?
Answer: This is because after @senx/cal/BUCKETIZE.bymonth, the series are bucketized, so that warpscript functions that take a bucketized GTS as input can be applied there, but after UNBUCKETIZE.CALENDAR, the result is not considered bucketized anymore.
Let's give an example of that.
Operate on monthly bucketized series
Say we want to calculate the temperature trend month by month compared to previous years in San Francisco.
Since temperatures are yearly seasonal, we can use the STL function to extract the trend and get rid of the seasonal part (so no more seasonal upswings and downswings). But STL can only be applied on bucketized series. No problem: we do @senx/cal/BUCKETIZE.bymonth, then STL, and finally UNBUCKETIZE.CALENDAR.
https://snapshot.senx.io/00059f91489d481e-0-1-26bafb617997bf8e
// Filter out San Francisco temperature data
[ @senx/dataset/temperature [] { 'city' 'San Francisco' } filter.bylabels ] FILTER
// convert to Celcius degrees and monthly bucketize
[ SWAP <% DROP 273.15 - %> LMAP bucketizer.mean ] @senx/cal/BUCKETIZE.bymonth 0 GET
// seasonal-trend decomposition
{ 'PERIOD' 12 } STL
// extract the trend and substract the first value
1 GET SORT DUP 0 ATINDEX 4 GET -
// unbucketize
UNBUCKETIZE.CALENDAR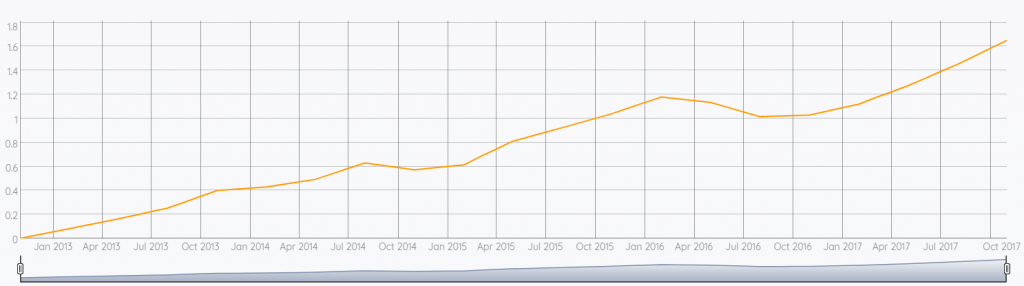
Bad news for San Francisco, global warming is quite impactful in this city!
We did this calculation for one city, but in WarpScript it is easy to expand a calculation to other time series. Let's do that and plot the min, mean and max of the trends among the cities of the dataset:
https://snapshot.senx.io/00059f914e42868b-0-4-6afbb38314c7a24f
// monthly bucketize
[ @senx/dataset/temperature <% DROP 273.15 - %> LMAP bucketizer.mean ] @senx/cal/BUCKETIZE.bymonth
// seasonal-trend decomposition
{ 'PERIOD' 12 } STL
// we extract the trend and substract the first value
<% DROP 1 GET SORT DUP 0 ATINDEX 4 GET - %> LMAP
// unbucketize
UNBUCKETIZE.CALENDAR 'trends' STORE
// reduce by min, mean, max
[ $trends [] reducer.min ] REDUCE { 'metric' 'min' } RELABEL
[ $trends [] reducer.mean ] REDUCE { 'metric' 'mean' } RELABEL
[ $trends [] reducer.max ] REDUCE { 'metric' 'max' } RELABEL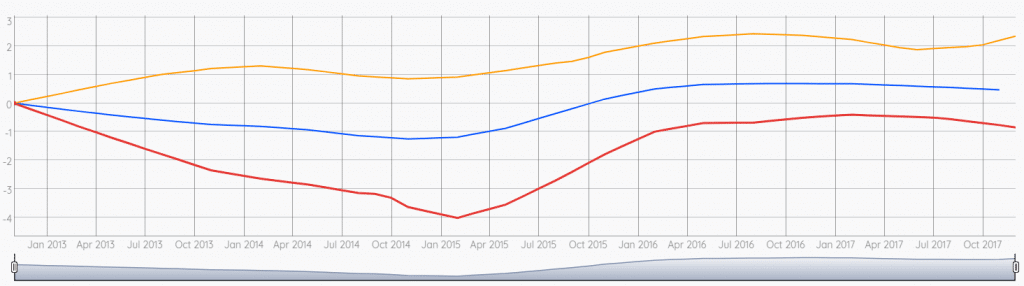
Globally the increasing trend is more moderate across other cities of the dataset.
BUCKETIZE by any calendar duration
To bucketize by a calendar duration efficiently, the last revision introduced 3 options:
In fact, the two macros are specific to monthly and yearly buckets, and wrap up the built-in function BUCKETIZE.CALENDAR that is more generic and gives more control over the bucket parameters.
To unbucketize, there is the built-in function UNBUCKETIZE.CALENDAR.
In addition to the bucketizer, BUCKETIZE.CALENDAR ask for three other parameters: lastbucket, bucketduration and bucketcount. A typical call looks like that:
[ $gts $bucketizer $lastbucket $bucketduration $bucketcount ] BUCKETIZE.CALENDARNote that these 3 operations also accept an optional $timezone parameter (a string) at the end of their argument list.
bucketcount
Like for BUCKETIZE, this is the number of resulting buckets. It can be set to 0 to be maximized.
bucketduration
This is the equivalent of the bucketspan for the BUCKETIZE framework. It is a string in ISO8601 duration format. For example, a bucketduration of one month can be chosen by using "P1M", a bucketduration of one month plus one week would be "P1M1W".
These durations take into account leap days and daylight saving time hour changes, but not leap seconds (as Unix timestamps neither do).
lastbucket
Like for BUCKETIZE, this is the end boundary (included) of the most recent bucket. However, unlike BUCKETIZE, BUCKETIZE.CALENDAR does not allow to calculate the lastbucket automatically by setting it to 0.
Nuances on lastbucket
This is like this not to introduce an incoherence with BUCKETIZE: when using BUCKETIZE, setting the lastbucket to 0 is the only case where if the input is a list of GTS, then the outputs can be unaligned (because each series can have a different computed lastbucket) ; but in the case of BUCKETIZE.CALENDAR, the output series would still be aligned since their ticks are bucket indices since Unix epoch (even though the real buckets are not aligned).
The lastbucket is an important parameter, since it defines how much the bucket containing the Unix Epoch is shifted from starting from it. This information is used to calendar-unbucketize by the function UNBUCKETIZE.CALENDAR.
For example, the lastbucket when using BUCKETIZE.bymonth is automatically computed such that the bucketindex equals 0 (i.e. each bucket starts at the beginning of a month and ends at the last time unit of this month). This is the same for BUCKETIZE.byyear.
Conclusion
In this article we have seen how to still use the BUCKETIZE framework and operations when working with calendar durations.
This allowed to aggregate by calendar duration that can be of irregular span (like months or years, for example), and to still be able to use WarpScript functions that work on bucketized series.
Read more
WarpStudio 2.0.6
FETCHez la data !
Build a WarpScript extension which embeds a C library

Machine Learning Engineer